In deze blog worden belangrijke visulisatiepakketten gepresenteerd alsmede een interessant bronnenoverzicht over dat onderwerp”.
Analyseren
Author
Harrie Jonkman
Published
May 2, 2024
Inleiding
Over datavisualisatie heb ik regelmatig een blog geschreven omdat dat onderwerp mij zo interesseert. Jarenlang volgde ik het werk van Kieran Healy met grote interesse. Onlangs kwam ik op R-bloggers het blog Data visualisatie opnieuw geladen tegen die voor mij belangrijke visualisatiepakketten weer eens goed samenvatHier. Tegelijk volgde ik op afstand de hele interessante cursus van Samantha Csik. Ik kan jullie aanraden daar eens naar te kijken.
In dit blog heb ik Data visualisatie opnieuw geladen bewerkt en het Samantha’s bronnenoverzicht (een klein onderdeel van haar cursus) toegevoegd. Dank jullie wel voor het delen van deze inzichten.
Datavisualisatie opnieuw geladen
In het enorme en steeds groter wordende universum van gegevens wordt het vermogen om de verhalen die in getallen verborgen zitten niet alleen te zien, maar ook echt te begrijpen, van het grootste belang. Daarom zijn krachtige hulpmiddelen voor creatie en inzicht zo belangrijk- datavisualisatiepakketten voor R, elk met zijn unieke mogelijkheden om ruwe data om te zetten in overtuigende verhalen.
Onze zoektocht verloopt via de veelzijdige landschappen van Quarto en R Markdown (Rmd), platforms die als ruggengraat dienen voor onze rapporten. Of je nu een interactief webdocument opstelt, een statische PDF of een netjes opgemaakt Word-bestand, deze tools zijn de doeken waarop onze dataverhalen zich zullen ontvouwen. Maar een canvas alleen maakt nog geen kunst - het zijn de penselen, kleuren en technieken die een scène tot leven brengen. Op dezelfde manier stellen de door ons gekozen R pakketten - elk een geniale penseelstreek - ons in staat om ingewikkelde schilderijen te maken met onze gegevens.
Dit artikel zal dienen als je gids door dit arsenaal aan visualisatiepakketten. Van de basis ggplot2 tot de interactieve plotly, de geospatiale leaflet, en de gedetailleerde gt voor tabulaire kunst, we zullen een spectrum van tools behandelen die tegemoet komen aan de behoeften van elke analist, onderzoeker en data storyteller. We gaan in op hoe elk pakket kan worden gebruikt binnen Quarto en R Markdown om rapporten te maken die niet alleen informatie overbrengen, maar ook je publiek boeien en informeren.
Als we samen aan deze reis beginnen, vergeet dan niet dat de kracht van deze tools niet alleen ligt in hun individuele mogelijkheden, maar in hoe ze gecombineerd kunnen worden om een samenhangend, boeiend verhaal te vertellen. Aan het einde van deze verkenningstocht ben je uitgerust met een divers en krachtig arsenaal, klaar om elke datavisualisatie-uitdaging aan te gaan die op je pad komt.
Laat de reis beginnen.
De basis met ggplot2
In het hart van ons datavisualisatie-arsenaal ligt ggplot2, een pakket dat een revolutie teweeg heeft gebracht in de manier waarop we denken over en grafieken maken in R. Geïnspireerd door Leland Wilkinson’s Grammar of Graphics, stelt ggplot2 gebruikers in staat om plots laag voor laag samen te stellen, waardoor het maken van complexe visualisaties zowel intuïtief als toegankelijk wordt.
ggplot2 blinkt uit in zijn vermogen om datavisualisatie op te splitsen en te begrijpen als een serie logische stappen: dataselectie, esthetische mapping, geometrische objecten en statistische transformaties. Deze gestructureerde aanpak stelt gebruikers in staat om bijna elk type grafiek te maken, van eenvoudige scatter plots tot ingewikkelde gelaagde visualisaties. De uitgebreide aanpassingsmogelijkheden van het pakket - door middel van schalen, thema’s en coördinaten - zorgen ervoor dat gebruikers hun visuals precies kunnen afstemmen op het verhaal dat ze willen overbrengen.
Voor rapporten in Quarto of R Markdown, fungeert ggplot2 als het basisgereedschap voor datavisualisatie. De veelzijdigheid is ongeëvenaard en biedt scherpe afbeeldingen van publicatiekwaliteit voor statische uitvoer (PDF, DOCX) en aanpasbare visuals voor dynamische HTML documenten. Of je nu een formeel rapport maakt, een uitgebreid academisch artikel of een boeiend webartikel, ggplot2 biedt de benodigde gereedschappen om het verhaal van je gegevens visueel weer te geven.
Om de kracht van ggplot2 te illustreren, laten we een eenvoudige maar elegante scatter plot maken:
Dit codefragment laat de eenvoud en elegantie van ggplot2 zien en creëert een plot die zowel visueel aantrekkelijk als informatief is. Terwijl we verder gaan met het verkennen van meer gespecialiseerde pakketten, blijft ggplot2 onze vertrouwde basis, zodat we erop kunnen voortbouwen en onze rapporten kunnen verrijken met verschillende visuele verhalen.
Interactiviteit verbeteren met plotly
In de dynamische wereld van web-gebaseerde rapportages, onderscheidt plotly zich als een baken van interactiviteit. Het bouwt voort op de statische schoonheid van ggplot2 plots door een laag van betrokkenheid toe te voegen door middel van interactieve elementen. Gebruikers kunnen met de muis over gegevenspunten bewegen, inzoomen op interessante gebieden en direct in hun plots door datasets filteren, waardoor een statische visualisatie verandert in een interactieve verkenning.
plotly biedt een breed scala aan interactieve grafiektypen, waaronder lijndiagrammen, staafdiagrammen, scatter plots en meer, allemaal met het extra voordeel van gebruikersinteractie. Het is bijzonder goed in het verwerken van grote datasets, waardoor het mogelijk is om complexe gegevens in real-time te onderzoeken en interpreteren. De mogelijkheid om het pakket te integreren met ggplot2 betekent dat gebruikers eenvoudig hun bestaande visualisaties van statisch naar dynamisch kunnen brengen met minimale inspanning.
Voor HTML-rapporten gemaakt in Quarto of R Markdown, verbetert plotly de ervaring van de lezer door de gegevensverkenning een integraal onderdeel van het verhaal te maken. Dit niveau van interactiviteit nodigt het publiek uit om zich op een dieper niveau met de gegevens bezig te houden, waardoor een meer persoonlijke verkenning van de bevindingen mogelijk wordt. Het is vooral nuttig in scenario’s waar het begrijpen van gegevensnuances cruciaal is, zoals bij verkennende gegevensanalyse of bij het presenteren van resultaten aan een divers publiek.
Zo transformeer je een ggplot2 plot in een interactieve plotly:
library(ggplot2)library(plotly)
Attaching package: 'plotly'
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
Warning in geom_point(aes(text = rownames(mtcars)), size = 4): Ignoring unknown
aesthetics: text
# Omzetten naar plotlyggplotly(p, tooltip ="text")
Deze code demonstreert het gemak waarmee een statische ggplot2 visualisatie kan worden omgezet in een interactieve plotly grafiek. Door plotly op te nemen in je toolkit voor het vertellen van data, ontgrendel je een wereld waarin datavisualisaties niet alleen worden gezien, maar ook ervaren.
Data in kaart brengen met leaflet
Georuimtelijke datavisualisatie is een kritisch aspect van verhalen vertellen op veel gebieden, van milieuwetenschap tot stedelijke planning. leaflet voor R brengt de kracht van interactieve kaarten naar uw rapporten, zodat u gedetailleerde, dynamische kaarten kunt maken die direct in HTML-documenten kunnen worden ingesloten. Gebaseerd op de Leaflet.js bibliotheek, is het de belangrijkste tool voor het bouwen van interactieve kaarten in het R ecosysteem.
Met leaflet kun je meerdere gegevensbronnen in lagen op één kaart plaatsen, het uiterlijk van kaarten aanpassen en interactieve functies zoals pop-ups en markeringen toevoegen. Het ondersteunt verschillende kaarttypen, waaronder basiskaarten van OpenStreetMap, Mapbox en Google Maps. Of je nu migratiepatronen volgt, gegevens over klimaatverandering visualiseert of demografische trends laat zien, leaflet maakt ruimtelijke gegevens toegankelijk en aantrekkelijk.
Voor Quarto of R Markdown rapporten bestemd voor het web, bieden leaflet kaarten een dynamische manier om geografische gegevens te presenteren. In tegenstelling tot statische kaarten, stelt leaflet lezers in staat om in en uit te zoomen, verschillende lagen te verkennen en direct te interageren met de datapunten. Deze interactiviteit verhoogt de betrokkenheid en het begrip van de gebruiker, waardoor leaflet een hulpmiddel van onschatbare waarde is voor rapporten die locatie-gebaseerde analyses of bevindingen bevatten.
Een interactieve kaart maken met leaflet is eenvoudig:
library(leaflet)# Voorbeelddata: Locaties van sommige belangrijke stedencities <-data.frame(lon =c(-74.00597, -0.127758, 151.20732),lat =c(40.71278, 51.50735, -33.86785),city =c("New York", "Londen", "Sydney"))# Maak een leaflet kaartleaflet(cities) %>%addTiles() %>%# Voeg de default OpenStreetMap kaartmarkeringen toeaddMarkers(~lon, ~lat, popup =~city)
Dit voorbeeld demonstreert hoe je een basis interactieve kaart maakt die specifieke locaties toont. Met leaflet wordt de complexiteit en diepte van uw ruimtelijke visualisaties alleen beperkt door uw verbeelding.
Interactieve tabellen met DT
Bij het presenteren van gegevens zijn tabellen onmisbaar om gedetailleerde informatie op een gestructureerde manier weer te geven. DT (DataTables) is een R pakket dat de jQuery DataTables plugin integreert en statische tabellen transformeert in interactieve verkenningstools. Het stelt gebruikers in staat om tabellen te doorzoeken, sorteren en pagineren direct in HTML-rapporten, waardoor de gebruiker beter in staat is om met de gegevens om te gaan en ze te begrijpen.
DT biedt een overvloed aan functies om tabellen interactiever en gebruiksvriendelijker te maken. Hoogtepunten zijn automatische of aangepaste kolomfiltering, opties voor tabelstyling en de mogelijkheid om knoppen op te nemen voor het exporteren van de tabel naar CSV, Excel of PDF-formaten. Deze functies zijn vooral handig in rapporten die grote datasets bevatten, zodat lezers kunnen navigeren en zich kunnen concentreren op de gegevens die hen het meest interesseren.
Voor rapporten gegenereerd in Quarto of R Markdown met een HTML uitvoer, biedt DT een superieure manier om tabelgegevens te presenteren. Het overbrugt de kloof tussen statische tabellen, die overweldigend en moeilijk te navigeren kunnen zijn, en de behoefte aan dynamische, toegankelijke datapresentatie. Of je nu onderzoeksresultaten, financiële gegevens of wetenschappelijke metingen samenvat, DT-tabellen kunnen de leesbaarheid en bruikbaarheid van je rapporten aanzienlijk verbeteren.
Hier is een eenvoudig voorbeeld van hoe je een interactieve tabel kunt maken met DT:
library(DT)# Voorbeelddata: Een deelset van de mtcars-datasetdata(mtcars)mtcars_subset <-head(mtcars, 10)# Render een interactieve tabeldatatable(mtcars_subset, options =list(pageLength =5, autoWidth =TRUE))
Dit codefragment demonstreert hoe je een subset van de mtcars dataset omzet in een interactieve tabel, compleet met paginering en instelbare kolombreedtes. Door DT in je rapportagetoolkit te integreren, kun je ervoor zorgen dat zelfs de dichtste gegevenstabellen navigeerbare en inzichtelijke onderdelen van je verhaal worden.
De grammatica van tabellen met gt
Terwijl DT zich richt op interactiviteit voor gegevenstabellen, brengt het gt pakket ongeëvenaarde niveaus van aanpassing en opmaak naar het maken van tabellen in R. Gt, dat staat voor “Grammatica van Tabellen”, stelt je in staat om zeer gedetailleerde en mooi opgemaakte tabellen te maken die informatie duidelijk en effectief communiceren, vergelijkbaar met hoe ggplot2 het maken van plotten revolutioneert.
Met gt kun je tabellen maken die verder gaan dan alleen de presentatie van gegevens; het stelt je in staat om een verhaal te vertellen met je gegevens. Van het toevoegen van voetnoten, het kleuren van cellen op basis van waarden, tot het maken van complexe lay-outs met gegroepeerde kopteksten en overspannen labels, gt biedt een uitgebreide reeks gereedschappen om de esthetische en functionele aspecten van tabellen in je rapporten te verbeteren.
In Quarto of R Markdown rapporten, ongeacht het uitvoerformaat (HTML, PDF of DOCX), kunnen gt tabellen de visuele standaard en leesbaarheid van je presentaties aanzienlijk verhogen. Vooral in PDF’s en geprinte documenten, waar interactieve elementen niet mogelijk zijn, maakt de gedetailleerde aanpassing die gt biedt uw tabellen niet alleen gegevenscontainers maar ook belangrijke verhalende elementen van uw rapport.
Om de mogelijkheden van gt te demonstreren, maken we een eenvoudige maar gestileerde tabel met een subset van de mtcars dataset:
library(gt)# Voorbeelddata: Een deelset van de mtcars datasetdata <-head(mtcars, 10)gt_table <-gt(data) %>%tab_header(title ="Motor Testen",subtitle ="Een deelverzameling van de mtcars-dataset" ) %>%cols_label(mpg ="Mijlen/(US:in gallon)",cyl ="Aantal cylinders",disp ="Verplaatsing (cu.in.)" ) %>%fmt_number(columns =vars(mpg, disp),decimals =2 ) %>%tab_style(style =cell_fill(color ="gray"),locations =cells_column_labels(columns =TRUE) ) %>%tab_style(style =cell_text(color ="white"),locations =cells_column_labels(columns =TRUE) )
Warning: Since gt v0.3.0, `columns = vars(...)` has been deprecated.
• Please use `columns = c(...)` instead.
Since gt v0.3.0, `columns = vars(...)` has been deprecated.
• Please use `columns = c(...)` instead.
Warning: Since gt v0.3.0, `columns = TRUE` has been deprecated.
• Please use `columns = everything()` instead.
Since gt v0.3.0, `columns = TRUE` has been deprecated.
• Please use `columns = everything()` instead.
gt_table
Motor Testen
Een deelverzameling van de mtcars-dataset
Mijlen/(US:in gallon)
Aantal cylinders
Verplaatsing (cu.in.)
hp
drat
wt
qsec
vs
am
gear
carb
21.00
6
160.00
110
3.90
2.620
16.46
0
1
4
4
21.00
6
160.00
110
3.90
2.875
17.02
0
1
4
4
22.80
4
108.00
93
3.85
2.320
18.61
1
1
4
1
21.40
6
258.00
110
3.08
3.215
19.44
1
0
3
1
18.70
8
360.00
175
3.15
3.440
17.02
0
0
3
2
18.10
6
225.00
105
2.76
3.460
20.22
1
0
3
1
14.30
8
360.00
245
3.21
3.570
15.84
0
0
3
4
24.40
4
146.70
62
3.69
3.190
20.00
1
0
4
2
22.80
4
140.80
95
3.92
3.150
22.90
1
0
4
2
19.20
6
167.60
123
3.92
3.440
18.30
1
0
4
4
Dit codefragment laat zien hoe je met gt niet alleen gegevens in tabellen kunt structureren en presenteren, maar ook artistieke expressie kunt geven aan gegevensrapportage, waardoor je tabellen zowel informatief als visueel aantrekkelijk worden.
Grafieken tot leven brengen met ggiraph
In de zoektocht om rapporten boeiender te maken, komt ggiraph naar voren als een krachtige bondgenoot, die de transformatie van statische ggplot2 grafieken in interactieve visuele verhalen mogelijk maakt. Met ggiraph kunnen elementen in ggplot2 plots, zoals punten, lijnen en balken, interactief worden door tooltips, hover acties en zelfs hyperlinks te ondersteunen. Deze interactiviteit verrijkt de gebruikerservaring, waardoor een diepere verkenning en begrip van de onderliggende gegevens mogelijk wordt.
Het ggiraph pakket blinkt uit wanneer je een laag van betrokkenheid wilt toevoegen aan je datavisualisaties. Hiermee kunnen kijkers met de muis over specifieke elementen gaan om meer details te zien of op delen van de grafiek klikken om externe bronnen te openen. Deze mogelijkheid is van onschatbare waarde voor online rapporten, waar lezersbetrokkenheid en interactiviteit van het grootste belang zijn.
Voor HTML-gebaseerde rapporten die zijn gemaakt met Quarto of R Markdown, verbetert ggiraph de mogelijkheden voor het vertellen van verhalen door van datavisualisaties een tweerichtings interactiekanaal te maken. Deze functie is vooral nuttig voor verkennende data-analyse, educatief materiaal, of elk rapport dat als doel heeft een meeslepende data-exploratie-ervaring te bieden. Hoewel ggiraph uitblinkt in webomgevingen, behouden de statische versies van deze verrijkte plots nog steeds hun esthetische en informatieve waarde in PDF of DOCX outputs.
Hier is een eenvoudig voorbeeld van hoe je een interactieve plot kunt maken met ggiraph, door gebruik te maken van een eenvoudige ggplot2 staafdiagram:
# Voorbeeld van#https://www.productive-r-workflow.com/quarto-tricks#ggiraph# Te goed om niet te delen# Op deze site vind je meer Quarto trucs. library(ggplot2)library(ggiraph)library(patchwork)# Voorbeelddata - die je door eigen data kunt vervangenmap_data <-data.frame(id =1:3,lat =c(40, 42, 37),lon =c(-100, -120, -95),group =c("A", "B", "C"))line_data <-data.frame(id =rep(1:3, each =10),time =rep(seq(as.Date("2021-01-01"), by ="1 month", length.out =10), 3),value =rnorm(30),group =rep(c("A", "B", "C"), each =10))# Kaart met interactieve puntenmap_plot <-ggplot() +borders("world", colour ="gray80", fill ="gray90") +# Voeg een wereldkaart op achtergrond toegeom_point_interactive(data = map_data, aes(x = lon, y = lat, size =5, color=group, tooltip = group, data_id = group)) +theme_minimal() +theme(legend.position ="none") +coord_sf(xlim =c(-130, -65), ylim =c(10, 75)) # Line chart with interactive linesline_plot <-ggplot(line_data, aes(x = time, y = value, group = group, color=group)) +geom_line_interactive(aes(data_id = group, tooltip = group))combined_plot <-girafe(ggobj = map_plot +plot_spacer() + line_plot +plot_layout(widths =c(0.35, 0, 0.65)),options =list(opts_hover(css =''),opts_hover_inv(css ="opacity:0.1;"), opts_sizing(rescale =FALSE) ),height_svg =4,width_svg =12)combined_plot
Dit voorbeeld gaat uit van een scenario waarbij klikken op een punt in de scatterplot (hier vereenvoudigd als klikken op een categorie) het histogram dynamisch zou bijwerken om de verdeling van waarden voor die categorie weer te geven.
Naadloze composities met patchwork
Terwijl ggiraph individuele plots tot leven brengt met interactiviteit, is patchwork het gereedschap voor het harmonieus combineren van meerdere ggplot2 plots in een samenhangende compositie. patchwork vereenvoudigt het proces van het rangschikken van meerdere plots, waardoor complexe lay-outs mogelijk zijn die een uniforme esthetiek behouden. Het is vergelijkbaar met het samenstellen van een visuele symfonie van individuele noten, waarbij elke plot zijn rol speelt in het overkoepelende verhaal van de gegevens.
patchwork blinkt uit in flexibiliteit en gebruiksgemak en biedt een syntaxis die zowel intuïtief als krachtig is. Je kunt plots verticaal, horizontaal en genest rangschikken en de afstand, uitlijning en zelfs gedeelde legenda’s regelen. Deze mogelijkheden zijn van onschatbare waarde wanneer je verschillende aspecten van je gegevens naast elkaar moet vergelijken of een verhaal met meerdere facetten moet vertellen door middel van een reeks visualisaties.
In zowel Quarto als R Markdown rapporten, ongeacht het uitvoerformaat, kun je met patchwork visueel aantrekkelijke en informatieve plotopstellingen maken. Voor statische rapporten (PDF, DOCX) kunnen deze composities helpen om complexe informatie in een verteerbaar formaat over te brengen. Voor HTML-rapporten voegt patchwork geen interactiviteit toe aan de plots zelf, maar de strategische rangschikking van visuele elementen kan de lezer helpen bij het verkennen van de gegevens.
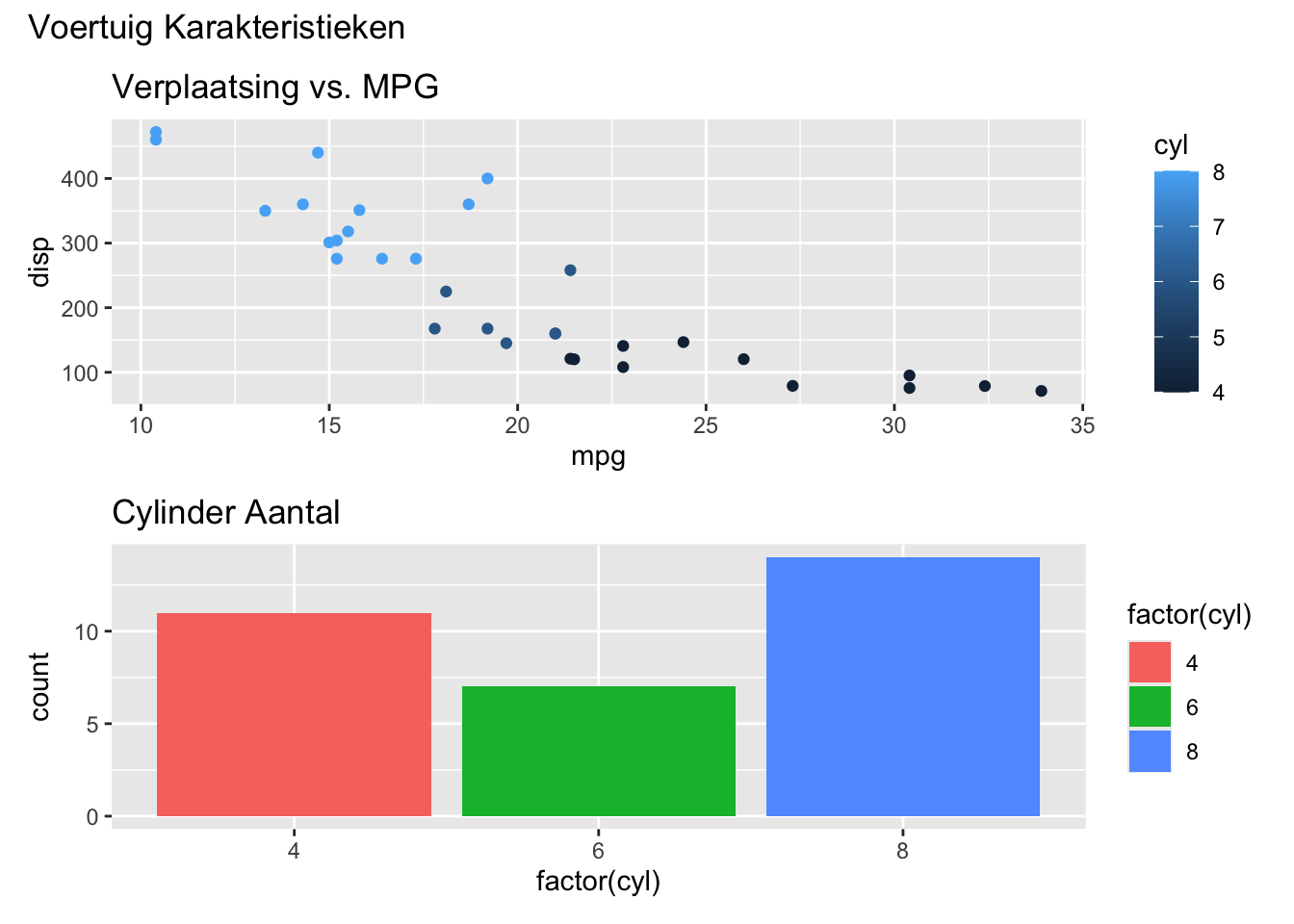
Laten we, om de kracht van patchwork te demonstreren, een samenstelling maken van twee eenvoudige ggplot2 plots:
library(ggplot2)library(patchwork)# Eerste grafiek: Een scatterplotp1 <-ggplot(mtcars, aes(mpg, disp)) +geom_point(aes(color = cyl)) +labs(title ="Verplaatsing vs. MPG")# Tweede grafiek: Een barplotp2 <-ggplot(mtcars, aes(factor(cyl))) +geom_bar(aes(fill =factor(cyl))) +labs(title ="Cylinder Aantal")# Combineer grafieken met patchworkplot_combo <- p1 + p2 +plot_layout(ncol =1, heights =c(1, 1)) +plot_annotation(title ="Voertuig Karakteristieken")# Weergave van de gecombineerde grafiekplot_combo
Dit voorbeeld laat zien hoe patchwork naadloos twee verschillende ggplot2 plots combineert tot een enkele, samenhangende visuele weergave. Door plots te rangschikken in een doordacht ontworpen lay-out, kunt u de verhalende impact van uw gegevensvisualisaties in rapporten verbeteren.
Meester worden over het visualisatiearsenaal
Onze reis door het landschap van R-pakketten voor het verbeteren van rapporten in Quarto en R Markdown weerspiegelt de cruciale scène uit The Matrix, waar een scala aan tools wordt opgeroepen met een duidelijke missie in gedachten. In ons verhaal vormen deze tools ggplot2, plotly, leaflet, DT, gt, ggiraph en patchwork een robuust arsenaal, elk met unieke mogelijkheden om onze datarapporten niet alleen informatief, maar ook boeiend en aantrekkelijk te maken. - ggplot2 legde de basis en bood een veelzijdig platform voor het maken van een breed scala aan plots met uitgebreide aanpassingsmogelijkheden, zodat elke grafiek precies de beoogde boodschap overbrengt. - plotly en ggiraph introduceerden interactiviteit en transformeerden statische afbeeldingen in dynamische conversaties, waarbij lezers werden uitgenodigd om de gegevens te verkennen en er interactief mee om te gaan.
- Met leaflet konden we onze verhalen in kaart brengen, geografische context bieden en locatiegegevens toegankelijker en begrijpelijker maken.
- Met DT en gt hebben we een revolutie teweeggebracht in de manier waarop we gegevens in tabelvorm presenteren, door dichte tabellen om te zetten in duidelijke, aantrekkelijke visuele elementen van onze rapporten. - Bij patchwork leerden we de kunst van compositie, waardoor we afzonderlijke plots konden verweven tot samenhangende visuele verhalen die de lezer naadloos door onze analyses leiden.
Elk van deze pakketten kan worden gezien als een ander type “vuurwapen” in ons arsenaal voor datavisualisatie, dat is uitgerust om specifieke uitdagingen en doelstellingen op het gebied van digitale verslaggeving aan te gaan. Of we nu streven naar duidelijkheid, betrokkenheid, interactiviteit of al het bovenstaande, onze gereedschapskist is nu volledig gevuld om elk gegevensverhaal tot leven te brengen.
Onthoud bij het afsluiten van deze verkenning dat de ware kracht van deze tools niet alleen ligt in hun individuele mogelijkheden, maar in hoe ze gecombineerd kunnen worden om een samenhangend, boeiend verhaal te vertellen. Net zoals Neo zijn arsenaal koos voor de missie die voor hem lag, heb jij nu de kennis om de juiste tools te kiezen voor jouw behoeften op het gebied van datavisualisatie, zodat je rapporten niet alleen worden gezien, maar ook worden onthouden.
Het landschap van data storytelling is enorm en verandert voortdurend, maar met dit arsenaal tot je beschikking ben je goed uitgerust om je stempel te drukken. Dus gebruik deze tools, verken hun potentieel en begin met het maken van dataverhalen die weerklank vinden, informeren en inspireren.
R for Data Science (2e), by Hadley Wickham, Mine Çetinkaya-Rundel, and Garrett Grolemund – een uitstekende inleiding op alles wat met R te maken heeft voor het bewerken, verkennen, visualiseren en communiceren van gegevens, grotendeels gericht op het gebruik van de {tidyverse}
ggplot2: Elegant Graphics for Data Analysis (3e), by Hadley Wickham, Danielle Navarro, and Thomas Lin Pedersen – nuttig voor het begrijpen van de onderliggende theorie van ggplot2 (OPMERKING: dit is momenteel (vanaf november 2023) een werk-in-uitvoering, en zoals de auteurs het zeggen, “een dumpplaats voor ideeën… we raden niet aan het te lezen” – het is nog steeds de moeite waard om het bestaan ervan te noteren zodat je er in de toekomst naar terug kunt keren!)
Data Visualization: A practical introduction, by Kieran Healy – een praktische inleiding tot de principes en praktijk van het bekijken en presenteren van gegevens met behulp van R en ggplot.
Hands-On Data Visualization, by Jack Dougherty and Ilya Ilyankou – leren hoe je verhalen kunt vertellen met je gegevens met behulp van drag-and-drop tools (bijv. Google Sheets, Datawrapper, Tableau Public)
A ggplot2 Tutorial for Beautiful Plotting in R, by Cédric Scherer – aeen blogpost die net zo goed een boek zou kunnen zijn; een uitstekende inleiding tot veel verschillende ggplot opties, ideeën en uitbreidingspakketten
Grafiektypen
From Data to Viz, by Yan Holtz & Conor Healy – een beslisboom om te bepalen welk grafiektype het meest geschikt is voor je gegevens
Chart Suggestions – A Thought-Starter, by A. Abela – een enkele pdf-beslisboom, die gebruikmaakt van de vier hoofdtypen grafieken om gebruikers te begeleiden bij het kiezen van een geschikte visualisatie
Subtleties of Color, by Robert Simmon – een zes-delige blogpostserie van ‘NASA Earth Observatory’ over het gebruik van kleur om aardobservatiegegevens in kaart te brengen
kleurkiezers & paletgeneratoren
{paletteer}: biedt algemene functies voor toegang tot een bijna uitgebreide lijst van paletten; bekijk ook zeker de R Color Palettes website, die previews bevat van alle paletten (als je erop klikt, zie je de {paletteer} code om het te gebruiken of de bijbehorende HEX-codes, samen met voorbeeldvisualisaties)
Palet Generator, door Learn UI Design – geef een of meer startkleuren op en dit hulpmiddel genereert een palet, enkele tint of afwijkend kleurenschema
Vis Palet, door Elijah Meeks and Susie Lu – een hulpmiddel dat laat zien hoe goed je gekozen kleuren werken voor kleine lijnen en grote vlakken, waarschuwt als je kleuren hebt die dezelfde naam hebben (wat het moeilijker kan maken om over je ontwerpen te praten, bijvoorbeeld in een presentatie) en kan kleurwaarnemingstekorten simuleren.
Shade Generator – een hulpmiddel voor het genereren van schaduwschalen
toegankelijkheid & kleuren
Veilig kleurenblinde kleurenschema’s, door het NCEAS Science Communication Resource Center – tips en voorbeelden van kleurenblind-vriendelijke kleurenpaletten
Kleuren =review, door Anton Robsarve – voor het begrijpen van voorgrond- en achtergrondcontrasten
Kleur Contrast Checker, by Userway: de kleurcontrastverhouding controleren en WCAG-nalevingsresultaten bekijken voor verschillende elementtypes
Kleur Contrast Checker, by coolors: controleer je kleurcontrastverhouding en gebruik hun verbeteringsgereedschap om je kleuren te verbeteren
Typografie
Google Lettertypen – catalogus van open-source lettertypen en pictogrammen, die kunnen worden geïmporteerd voor gebruik met{ggplot2}; controleer deze collectie van korte artikelen over het kiezen van lettertype
fontpair – gratis lettertypen en lettercombinaties
Word wakker & ruik de lettertypen, door Sarah Hyndman – een geweldige 14 minuten durende TEDx-talk over hoe lettertypen woorden omzetten in verhalen die de perceptie van het publiek kunnen beïnvloeden
#TidyTuesday alt tekst instructies – een eenvoudige formule voor het schrijven van alt-tekst voor datavisualisaties, zoals aanbevolen voor #TidyTuesday deelnemers
Racial Equity GIS Hub, by ESRI – een doorlopend, voortdurend groeiend resource-hub om organisaties te helpen die zich inzetten om raciale ongelijkheden aan te pakken; het bevat gegevenslagen, kaarten, toepassingen, trainingsbronnen, artikelen over best practices, oplossingen en voorbeelden van hoe Esri-gebruikers van over de hele wereld GIS gebruiken om raciale ongelijkheden aan te pakken
Northstar in GIS – een non-profitorganisatie die het werk en talent van zwarte professionals in GIS, geografie en bèta/techniek onder de aandacht brengt; technologie laat zien die raciale rechtvaardigheid bevordert en saamhorigheid en samenwerking stimuleert voor zwarte GIS-studenten, docenten, ondernemers, professionals en bondgenoten.
Tidy Tuesday, van Jon Harmon – een wekelijkse (zeer korte, ~5 minuten durende) podcast waarin een visualisatie (of een paar) wordt besproken die door leden van de community is (zijn) gemaakt met behulp van de nieuwste gepubliceerde dataset; Jon beschrijft de visualisatie en beschrijft een aantal belangrijke geomen en/of functies die de auteur heeft gebruikt om de visualisatie te maken
Data is Plural, door Jeremy Singer-Vine – een nieuwe podcast van de langlopende nieuwsbrief Data Is Plural, waarin elke aflevering een interview met een expert in 15 minuten wordt samengevat en je wordt meegenomen achter de schermen van een andere verrassende dataset.
Grainger S, Mao F, Buytaert W (2016) Environmental data visualisation for non-scientific contexts: Literature review and design framework. Environmental Modelling & Software. 85:299-318. https://doi.org/10.1016/j.envsoft.2016.09.004
Climate Viz, door Datawrapper – een verzameling blogberichten over datavisualisaties gemaakt met Datawrapper die ons (en hopelijk jou) helpen om de opwarming van de aarde te begrijpen en wat de mensheid ertegen kan doen
Jazz up your ggplots!, by Elmera Azadpour, Althea Archer, Hayler Corson-Dosch & Cee Nell at USGS – een geweldige blogpost met voorbeeld USGS viz + code; blijf op de hoogte van coole datagebeurtenissen bij USGS in hun Water Data For The Nation Blog
samengestelde lijsten
awesome-ggplot2, door Erik Gahner Larsen – een lijst met geweldige ggplot2-tutorials, pakketten enz.
Inspirerende makers van datavisualisatie
{ggplot2} makers
(Naar mijn eerlijke mening) Een van de beste manieren om te leren hoe je spannende ggplots maakt, is door te kijken naar code die anderen hebben geschreven. Hier zijn een paar mensen die echt ongelooflijk werk doen (samen met hun repo’s waar ze vaak hun creaties laten zien):
Maker
{{< fa brands github >}} Data Vis Repository (en andere online materialen)
Beperk je zeker niet tot alleen {ggplot2} makers! Er zijn zoveel ongelooflijke data verhalen-vertellers en informatie-ontwerpers om inspiratie uit te putten en van te leren. Een paar voorbeelden:
Kinga Stryszowska-Hill (die R / {ggplot2} gebruikt, naar andere datavisualisatie gereedschappen)
Databronnen
Data zijn er overal, maar dat betekent niet dat ze per se makkelijk op te sporen zijn. Hier zijn een aantal plaatsen waar ik gegevens heb gevonden en gebruikt (of in ieder geval heb overwogen om gegevens te gebruiken). Als jij een koele databron hebt gevonden (vooral als het een bron van milieugegevens is), dan zou ik dat graag willen weten! Het kan me helpen om lesmateriaal op te bouwen met nieuwe/andere voorbeelden, en het kan ook je collega’s helpen die misschien op zoek zijn naar soortgelijke gegevens. Overweeg alsjeblieft om gegevensbronnen bij te dragen via [dit Google-formulier] (https://forms.gle/uYC7eEie1XZ7D4Xm6).
data repository’s
DataOne – een opslagplaats van gegevensopslagplaatsen! Zoek in alle aangesloten archieven (inclusief archieven zoals EDI Data Portal, Arctic Data Center, KNB, enz.) naar milieugegevens (samen met gecureerde metadatarecords).
EDI Data Portal – bevat milieu- en ecologische gegevens en metadata die afkomstig zijn van met overheidsgeld gefinancierd onderzoek dat wordt bijgedragen door een aantal deelnemende organisaties (EDI is bijvoorbeeld de belangrijkste opslagplaats voor alle Long Term Ecological Research (LTER) data)
nieuwsbrieven / dataverzamelingen
ESIIL Data Library – De databibliotheek van het Environmental Data Science Innovation and Inclusion Lab (ESIIL), met een breed scala aan datasets, elk met een eigen webpagina.
Data is Plural – een wekelijkse nieuwsbrief (en seizoensgebonden podcast) van nuttige / merkwaardige datasets, gepubliceerd door Jeremy Singer-Vine
tidytuesday – een wekelijks sociaal dataproject waarbij minimaal opgeschoonde datasets over verschillende onderwerpen worden gedeeld zodat de R4DS-gemeenschap deze kan visualiseren; organisatoren delen links naar de originele databronnen en de scripts die zijn gebruikt om ze op te schonen voordat ze worden gepubliceerd
awesome-public-datasets – een archief met een lijst van hoogwaardige, themagecentreerde openbare gegevensbronnen
Information is Beautiful – Opgezet door David McCandless, Information is Beautiful is gewijd aan het inzichtelijk maken van de wereld met grafische en data-visuals. Ons doel is om uit te leggen, te distilleren en te verduidelijken. Al onze visualisaties zijn gebaseerd op feiten en gegevens: voortdurend bijgewerkt, herzien en herzien.
Kaggle Datasets – Kaggle is een online community voor datawetenschappers en beoefenaars van machine learning om gegevens te vinden en te publiceren, en om deel te nemen aan wedstrijden om uitdagingen op het gebied van datawetenschap op te lossen.
{tidycensus} package – waarmee R-gebruikers eenvoudiger kunnen interfacen met een select aantal data-API’s van het [US Census Bureau] (https://www.census.gov/) en tidyverse-klare dataframes kunnen retourneren.
Lerende gemeenschappen
online gemeenschappen
TidyTuesday, by the R4DS Online Learning Community – een wekelijks dataproject in R, en een uitstekende (durf ik te zeggen, de beste) manier om je datawrangling & visualisatievaardigheden te oefenen ### lokale gemeenschappen
Hier stonden de Santa Barbara gemeenschappen. Deze heb ik vervangen door twee Amsterdamse initiatieven.
NSC-R Workshops serie online workshops van een uur waarin participanten data science principes leren en oefenen in R en waarin principes van open science worden toegepast. Hier ben ik zelf bij betrokken en hier heb ik de website voor gemaakt.
R-Ladies Amsterdam – een lokale R-Ladies-groep die regelmatig bijeenkomt om te leren, te oefenen en te netwerken met andere R-gebruikers in Amsterdam