Hoe voer je een geclusterde logistische regressie uit vanuit een Bayesiaans perspectief? Aan de hand van data over succes en falen van Himalayaexpedities en leeftijd en zeestofgebruik van klimmers wordt duidelijk gemaakt hoe dit werkt. Deze blog is een bewerking van een deel van een hoofdstuk uit het prachtige Bayes Rules! boek.
modelleren
Bayesiaans
Author
Alicia A. Johnson e.a., bewerking HarrieJonkman
Published
December 13, 2022
Inleiding
Onlangs verscheen een prachtig boek van Alicia A. Johnson, Miles Q. Ot en Mine Dogucu onder de titel Bayes Rules! An Introduction to Applied Bayesian Modeling en het verscheen bij CRC Press (2022). Eerdere versies stonden kon je al via bookdown bekijken hier en vanaf de eerste keer dat ik het zag, was ik hier heel enthousiast over. Het boek heb ik direct besteld en met groot enthousiasme gelezen.
Het boek bestaat uit vier duidelijke delen. Het eerste deel gaat in op de fundamenten van het Bayesiaanse perspectief. Het leert je denken als een Bayesiaan en het gaat in op die belangrijke Bayesiaanse regel \(posterior=\frac{prior.likelihood}{normaliserende constante}\). Aan de hand van enkele voorbeelden gaan Johnson e.a. in op hoe het in de praktijk werkt. Daarna gaat het in op hoe kennis en data op elkaar inwerken en het laat enkele basisanalyses zien en hoe dat in deze vorm van statistiek werkt (normaal, binair en poisson). Het tweede deel is een meer technisch hoofdstuk en laat je ook onder de moterkap van deze techniek kijken. Het gaat ook op de wetenschappelijke principes van de benadering, waar je hier op moet letten, hoe je hiermee hypothesen kunt testen (niet alleen tov van een nulhypothese, maar hoeveel beter de ene hypothese is ten opzichte van de andere hyposthese) en hoe je hiermee ook kunt voorspellen. De twee volgende delen (Deel drie en vier) zijn praktische delen. Deel drie gaat in op regressieanalyses voor continue variabelen en classificatieanalyses voor binaire variabelen. Het vierde deel ten slotte gaat in op geclusterde datasets en hoe je hierarchische Bayesiaanse regressie en classificatieanalyses uitvoert.
Natuurlijk, er zijn onderhand al verschillende interessante boeken te krijgen die je laten zien hoe Bayesiaanse denken in de praktijk kan werken. De boeken van Gelman, McElreath, Spiegelhalter en Kruschke verschenen de afgelopen tien/vijftien jaar en leren je dit. Maar Bayes Rules! vind ik op dit moment als introductieboek mogelijk wel het beste.
Over het boek heb ik al eerder blogs geschreven. Hieronder zie je een bewerking van een deel van het achttiende hoofdstuk van het vierde deel (Non-Normal Hierarchical Regression & Classification). Dit zo overzetten is voor mij niet alleen een goede manier om het mij eigen te maken, maar ook een manier om het boek anderen aan te raden. Dus lezen en gebruiken deze Bayes Rules! An Introduction to Applied Bayesian Modeling. Dat is wat ik graag idereen aanraad.
Hierarchische logistische regressie
Eerst maar een enkele pakketten laden:
# Laden van pakkettenlibrary(bayesrules)library(tidyverse)
This is bayesplot version 1.9.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
library(rstanarm)
Loading required package: Rcpp
This is rstanarm version 2.21.3
- See https://mc-stan.org/rstanarm/articles/priors for changes to default priors!
- Default priors may change, so it's safest to specify priors, even if equivalent to the defaults.
- For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores())
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
Bergbeklimmers proberen grote hoogten te beklimmen in de majestueuze Nepalese Himalaya. Dit doen ze vanwege de sensatie van ijle lucht, de uitdaging of het buitenleven. Succes is niet gegarandeerd; slecht weer, defecte uitrusting, verwondingen of gewoon pech zorgen ervoor dat niet alle klimmers hun bestemming bereiken. Dit roept enkele vragen op. Hoe groot is de kans dat een bergbeklimmer de top wel haalt? Welke factoren kunnen bijdragen aan een hoger succespercentage? Naast het vage gevoel dat een gemiddelde klimmer 50% kans op succes heeft, wegen we dit zwak informatief inzicht af tegen data van klimmers die in het bayesrules pakket zitten. Dit deel van de data is beschikbaar gesteld door ‘The Himalayan Database’ (2020) en verspreid via het #tidytuesday project (R for Data Science 2020b):
De dataset climbers bevat de resultaten van 2076 klimmers vanaf 1978 tot en met 2019. Slechts 38,87% van hen slaagde erin de top te bereiken:
nrow(climbers)
[1] 2076
climbers %>%tabyl(success)
success n percent
FALSE 1269 0.6112717
TRUE 807 0.3887283
Omdat member_id in essentie een rij van klimmersid is en we maar één observatie per klimmer hebben, is dit geen groepsvariabele. Verder, het seizoen (seison), rol bij de expeditie (expedition_role) en het gebruik van zuurstof (oxygen_used) zijn categorische variabelen die meerdere malen zijn geobserveerd. Het zijn potentiële voorspellers van succes (succes), maar ook geen groepsvariabele. Dan blijft expeditie_id (expedition_id) over - dit is wel een groepsvariabele. De dataset beslaat 200 verschillende expedities:
# Omvang per expeditieclimbers_per_expedition <- climbers %>%group_by(expedition_id) %>%summarize(count =n())# Aantal expeditiesnrow(climbers_per_expedition)
[1] 200
Elke expeditie bestaat uit meerdere klimmers. Zo vertrokken onze eerste drie expedities met respectievelijk 5, 6 en 12 klimmers:
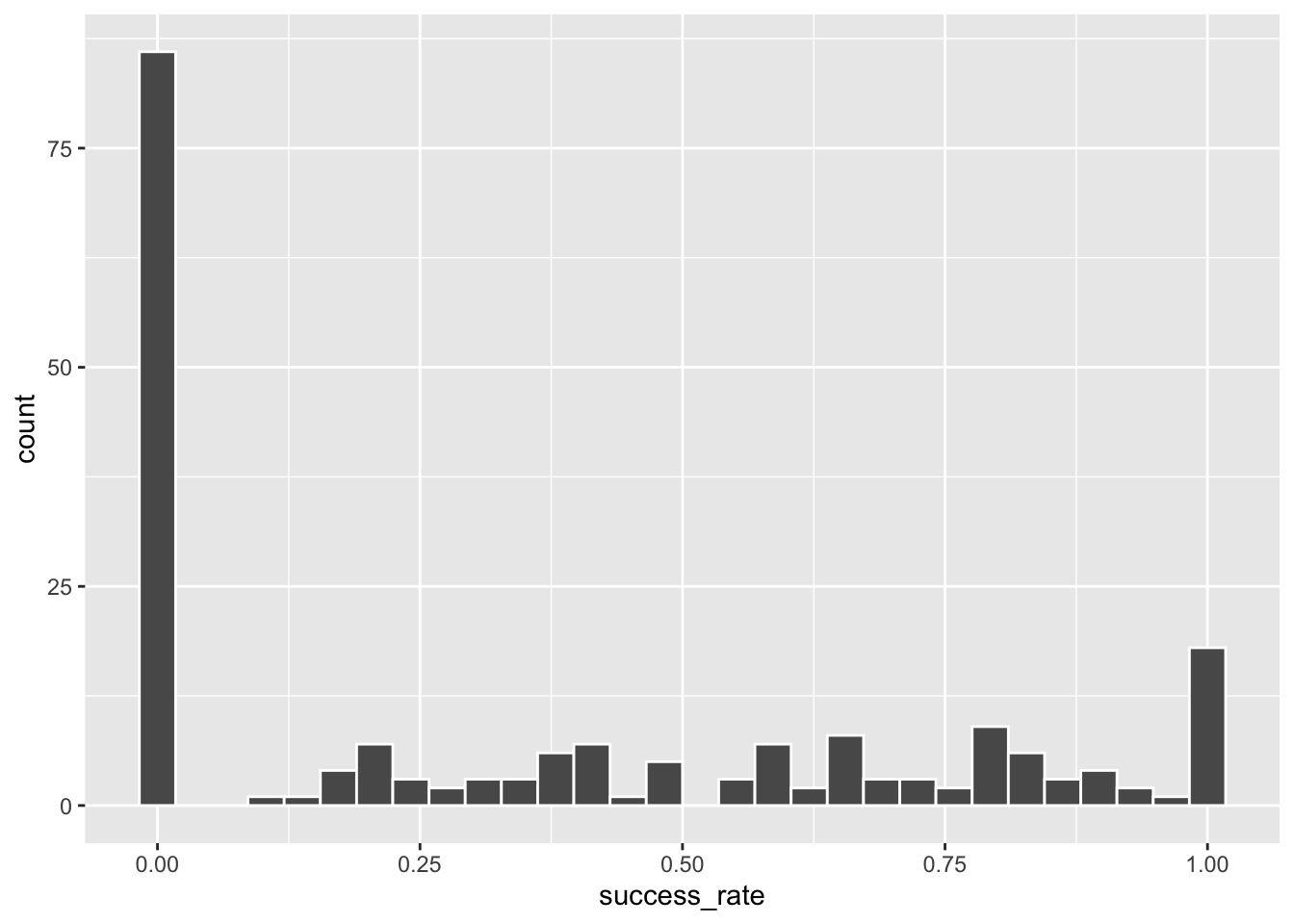
Het zou fout zijn om deze groepsstructuur te negeren en er anders van uit te gaan dat de individuele klimmers onafhankelijke resultaten boeken. Aangezien elke expeditie als een team werkt, hangt het succes of falen van de ene klimmer in díe expeditie gedeeltelijk af van het succes of falen van anderen in de groep. Bovendien vertrekken alle leden van een expeditie met dezelfde bestemming, met dezelfde leiders en onder dezelfde weersomstandigheden, en zijn dus onderhevig aan dezelfde externe succesfactoren. Het is dus niet alleen juist om rekening te houden met de groepering van de gegevens, maar het kan ook duidelijk maken in welke mate deze factoren variabiliteit veroorzaken in de succespercentages tussen expedities. Meer dan 75 van onze 200 expedities hadden een 0% succesratio - m.a.w. geen enkele klimmer in deze expedities slaagde erin de top te bereiken. Daarentegen hadden bijna 20 expedities een 100% succespercentage. Tussen deze extremen in, is er heel wat variatie in het succespercentage van de expedities.
# Bereken de slagingskans voor elke expeditieexpedition_success <- climbers %>%group_by(expedition_id) %>%summarize(success_rate =mean(success))
# Plot de slagingskansen over de expeditiesggplot(expedition_success, aes(x = success_rate)) +geom_histogram(color ="white")
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Model bouw en simulatie
Om de ‘gegroepeerde’ aard van onze gegevens te weerspiegelen, geeft \(Y_ij\) aan of klimmer \(i\) in expeditie \(j\) succesvol de top van hun piek bereikt:
\[\
Y_ij = \begin{cases}
1 Ja \\
0 Nee\\
\end{cases}
\]\] Er zijn verschillende potentiële voorspellers voor het succes van klimmers in onze dataset. We kijken hier naar slechts twee voorspellers: de leeftijd van de klimmer en of hij extra zuurstof heeft gekregen om gemakkelijker te kunnen ademen op grote hoogte. Als zodanig, definiëren we: \[ X_ij1=leeftijd van klimmer *i* in expeditie *j*\]
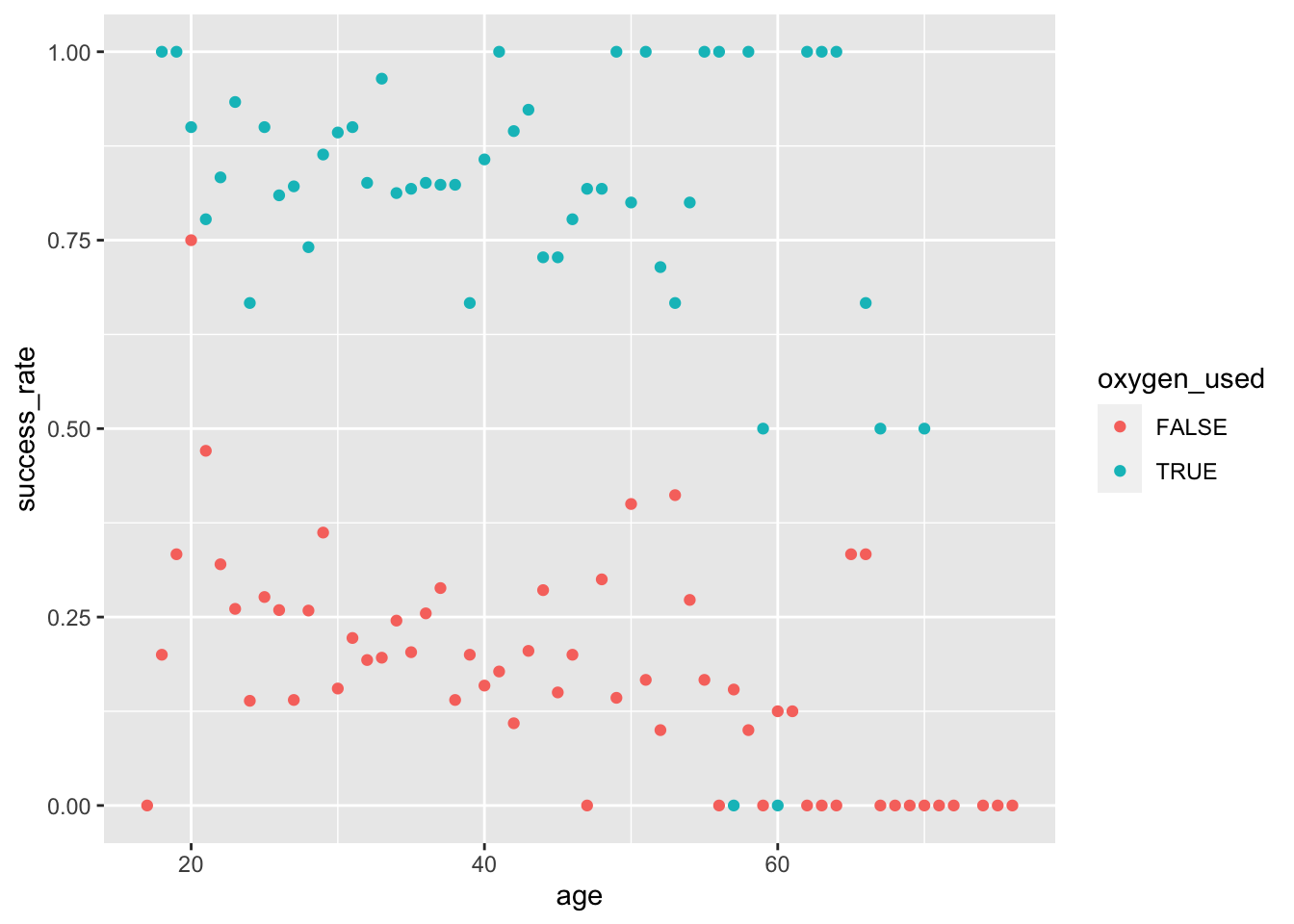
\[X_ij2=of de klimmer in *i* in expeditie *j* zuurstof (oxygen) heeft gekregen\] Door het aandeel van succes te berekenen bij elke combinatie van leeftijd en zuurstofgebruik, krijgen we een idee van hoe deze factoren gerelateerd zijn aan het klimmerssucces (zij het dat het een wankel idee is gezien de kleine steekproefgroottes van sommige combinaties). Kort samengevat lijkt het erop dat het succes van klimmers afneemt met de leeftijd en sterk toeneemt met het gebruik van zuurstof:
# Bereken het slagingspercentage per leeftijd en zuurstofgebruikdata_by_age_oxygen <- climbers %>%group_by(age, oxygen_used) %>%summarize(success_rate =mean(success))
`summarise()` has grouped output by 'age'. You can override using the `.groups`
argument.
# Plot deze relatieggplot(data_by_age_oxygen, aes(x = age, y = success_rate, color = oxygen_used)) +geom_point()
Om een Bayesiaans model van deze relatie op te stellen, erkennen we eerst dat het Bernoulli model redelijk is voor onze binaire responsvariabele \(Y_ij\). Stel \(\pi_ij\) de waarschijnlijkheid is dat klimmer_\(i\) in expeditie_\(j\) zijn piek succesvol beklimt, d.w.z. dat \(Y_ij=1\),
\[Y_ij|\pi_ij \sim \Bern{\pi_ij}\] Dit is een complete pooling benadering waarbij een simpel model wordt omgezet in een logistisch regressiemodel van \(Y\) met enkele voorspellers \(X\)
$$Y_ij|_0,_1,beta_2 ^{ind} (_ij) with log()=_0+_1X_ij1+_2X_ij2) \
Dit is een goed begin, MAAR het houdt geen rekening met de groepsstructuur van onze data. Overweeg in plaats daarvan het volgende hiërarchische alternatief met onafhankelijke, zwak informatieve priors hieronder afgestemd via stan_glmer() en met een prior model voor \(beta_0\) uitgedrukt via het gecentreerde intercept \(beta_0c\). Het is immers zinvoller om na te denken over de baseline succesratio bij de typische gemiddelde klimmer, \(\beta_0c\), dan bij 0-jarige klimmers die geen zuurstof gebruiken, \(\beta_0\)$. Daarom begonnen we onze analyse met de zwakke veronderstelling dat de typische klimmer een kans op succes heeft van 0,5, of met log(kans op succes)=0.
Net zo goed kunnen we dit logistische regressiemodel met willekeurige intercepts omvormen door de expeditiespecifieke intercepties uit te drukken als aanpassingen op het algemene intercept,
\[log(\frac{\pi_ij}{1-\pi_ij})=(\beta_0+b_0j) +\beta_1X_ij1 + \beta_2X_ij2\] met \(\beta_0j|\sigma_0 \sim^{ind} N(0,\sigma_0^2)\) Laten we eens naar de betekenis van en de veronderstellingen achter de modelparameters kijken:
De expeditie-specifieke intercepten \(\beta_0j\) beschrijven de onderliggende succespercentages, zoals gemeten door de log(kans op succes), voor elke expeditie\(j\). Hiermee wordt erkend dat sommige expedities inherent succesvoller zijn dan andere.
De expeditiespecifieke intervallen \(\beta_0j\) worden verondersteld normaal verdeeld te zijn rond een gemiddeld intercept \(\beta_0\) met standaardafwijking \(\sigma_0\). Daarmee beschrijft \(\beta_0\) het typische basissucces over alle expedities, en \(\sigma_0\) de tussen-groep variabiliteit in succespercentages van expeditie tot expeditie.
\(\beta_1\) beschrijft het gemiddelde verband tussen succes en leeftijd wanneer gecontroleerd wordt voor zuurstofgebruik. Op dezelfde manier beschrijft \(\beta_2\) de gemiddelde relatie tussen succes en zuurstofverbruik wanneer gecontroleerd wordt voor leeftijd.
Samengevat maakt ons logistisch regressiemodel met willekeurige intercepten de vereenvoudigende (maar volgens ons redelijke) veronderstelling dat expedities unieke intercepten\(\beta_0j\) kunnen hebben, maar delen de gemeenschappelijke regressieparameters \(\beta_1\) en \(\beta_2\). Anders gezegd, hoewel de onderliggende succespercentages kunnen verschillen van expeditie tot expeditie, zijn jonger zijn of zuurstof gebruiken niet voordeliger in de ene expeditie dan in de andere.
Om de posterior van het model te simuleren, combineert de stan_glmer() code hieronder het beste van twee werelden: family = binomial geeft aan dat het om een logistisch regressiemodel gaat en de (1 | expeditie_id) term in de modelformule incorporeert onze hiërarchische groeperingsstructuur:
Houdt de betekenis en assumpties erachter in je hoofd, want dat zijn de modelparameters:
climb_model <-stan_glmer( success ~ age + oxygen_used + (1| expedition_id), data = climbers, family = binomial,prior_intercept =normal(0, 2.5, autoscale =TRUE),prior =normal(0, 2.5, autoscale =TRUE), prior_covariance =decov(reg =1, conc =1, shape =1, scale =1),chains =4, iter =5000*2, seed =84735)
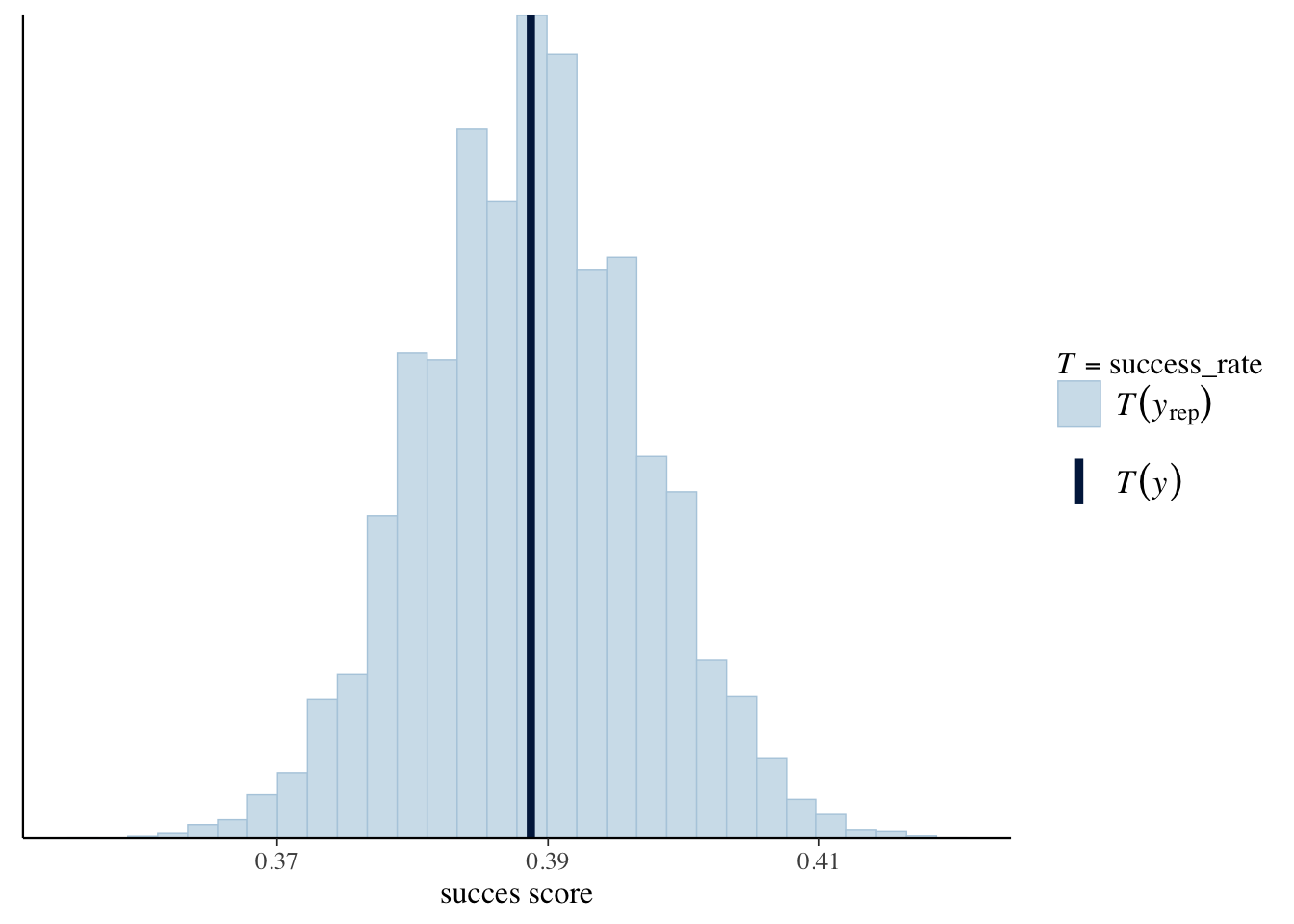
Terwijl deze diagnostiek bevestigt dat onze MCMC simulatie op het juiste spoor zit, geeft ook de posterior predictive check van hieronder aan dat ons model op het juiste spoor zit. Van elk van de 100 posterior gesimuleerde datasets, stellen we de proportie klimmers vast die succesvol waren met de success_rate() functie. Deze succespercentages variëren van ruwweg 37% tot 41%, in een klein venster rond het werkelijk waargenomen succespercentage van 38.9% in de klimmers data.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Posterior analyse
In onze posterior analyse van het succes van bergbeklimmers, concentreren we ons op het geheel. Behalve dat we gerustgesteld zijn door het feit dat we correct rekening houden met de groepsstructuur van onze gegevens, zijn we niet geïnteresseerd in een specifieke expeditie. Hieronder volgen enkele posterior samenvattingen voor onze regressieparameters \(\beta_0\), \(\beta_1\) en \(\beta_2\).
Om te beginnen zien we dat het 80% posterior ‘çredible’ (geloofwaardigheids) interval (CI) voor de age coëfficiënt \(\beta_1\) ruim onder 0 ligt. We hebben dus significant posterior bewijs dat, wanneer we controleren of een klimmer al dan niet zuurstof gebruikt, de kans op succes afneemt met de leeftijd. Meer specifiek, als we de informatie in \(\beta_1\) vertalen van de log(kansen) naar de kans schaal, is er 80% kans dat de kans op een succesvolle beklimming daalt tussen 3,5% en 5,8% voor elk jaar extra leeftijd: \(e^{-0,0594}, e^{-0,0358}=(0,942, 0,965)\).
Op dezelfde manier levert het 80% posterior geloofwaardig interval voor de oxygen_usedTRUE coëfficiënt \(beta_2\)significant posterior bewijs dat, wanneer gecontroleerd wordt voor leeftijd, het gebruik van zuurstof de kans op het beklimmen van de top drastisch verhoogt. Er is een kans van 80% dat het gebruik van zuurstof kan overeenkomen met een 182- tot 617-voudige toename van de kans op succes: \(e^{5.2}}, e^{6.44}=(182,617)\), Zuurstof alstublieft!
Door onze waarnemingen voor \(\beta_1\) en \(\beta_2\) te combineren, wordt het posterior mediaan model voor de relatie tussen de log(kans op succes) van de klimmers en hun leeftijd (\(X_1\))en zuurstofgebruik (\(X_2\)) \[log(\frac{\pi}{1-\pi})=-1.42-0.0474X_1+5.80X_2\]
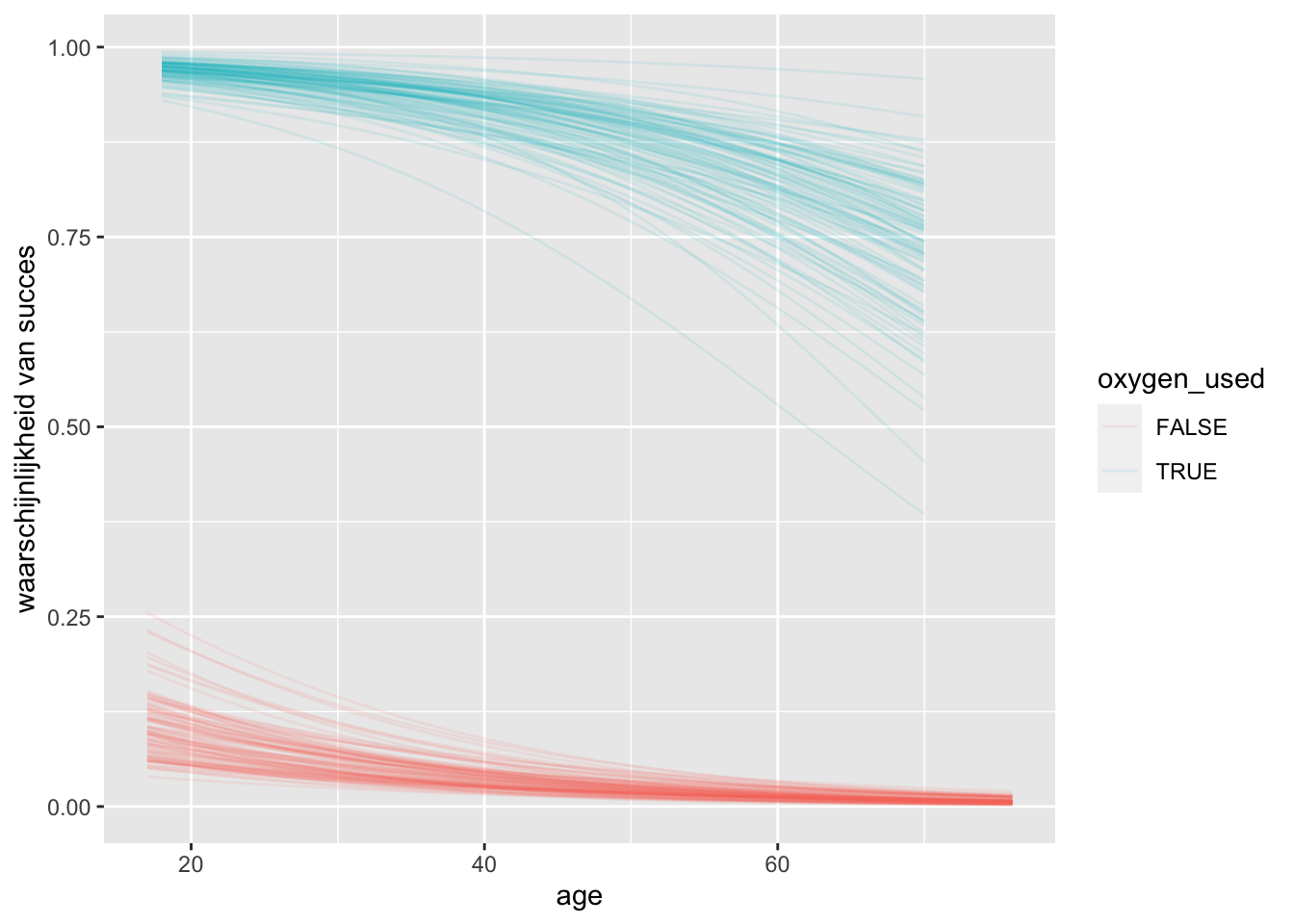
Of, op de schaal van waarschijnlijkheid: \[\pi=\frac{e^{-1.42-0.0474X_1+5.80X_2}}{1+e^{-1.42-0.0474X_1+5.80X_2}}\] Dit posterior mediaan model vertegenwoordigt slechts het midden van een bereik van posterior plausibele relaties tussen succes, leeftijd en zuurstofgebruik. Om een idee te krijgen van dit bereik, toont figuur hieronder 100 posterior plausibele alternatieve modellen. Zowel met als zonder zuurstof neemt de kans op succes af met de leeftijd. Bovendien, op elke leeftijd, is de kans op succes dramatisch hoger wanneer klimmers zuurstof gebruiken. Echter, onze zekerheid over deze trends varieert nogal per leeftijd. We hebben veel minder zekerheid over de slaagkans voor oudere klimmers met zuurstof dan voor jongere klimmers met zuurstof, voor wie de slaagkans over het geheel hoog is. Op dezelfde manier, maar minder drastisch, hebben we minder zekerheid over de slaagkans voor jongere klimmers die geen zuurstof gebruiken dan voor oudere klimmers die geen zuurstof gebruiken, voor wie de slaagkans uniform laag is.
climbers %>%add_fitted_draws(climb_model, n =100, re_formula =NA) %>%ggplot(aes(x = age, y = success, color = oxygen_used)) +geom_line(aes(y = .value, group =paste(oxygen_used, .draw)), alpha =0.1) +labs(y ="waarschijnlijkheid van succes")
Warning: `fitted_draws` and `add_fitted_draws` are deprecated as their names were confusing.
Use [add_]epred_draws() to get the expectation of the posterior predictive.
Use [add_]linpred_draws() to get the distribution of the linear predictor.
For example, you used [add_]fitted_draws(..., scale = "response"), which
means you most likely want [add_]epred_draws(...).
Posterior classificatie
Stel dat vier klimmers op een nieuwe expeditie gaan. Twee van hen zijn 20 jaar oud en twee zijn 60 jaar. Van beide leeftijdsgroepen is één klimmer van plan zuurstof te gebruiken en de andere niet:
age oxygen_used expedition_id
1 20 FALSE new
2 20 TRUE new
3 60 FALSE new
4 60 TRUE new
Natuurlijk willen ze allemaal weten hoe groot de kans is dat ze de top zullen bereiken. Om dit vast te stellen werken we hier met de posterior_predict() snelkoppelingsfunctie om 20.000 posterior voorspellingen (0 of 1) te simuleren voor elk van onze 4 nieuwe klimmers:
# Posterior voorspellingen van binaire uitkomstset.seed(84735)binary_prediction <-posterior_predict(climb_model, newdata = new_expedition)# Eerste drie voorspellingenhead(binary_prediction, 3)
1 2 3 4
[1,] 0 0 0 1
[2,] 0 1 0 1
[3,] 0 1 0 0
Voor elke klimmer wordt de kans op succes benaderd door het geobserveerde aandeel van succes onder hun 20.000 posterieure voorspellingen. Aangezien deze kansen de onzekerheid in het basissuccespercentage van de nieuwe expeditie omvatten, zijn ze gematigder dan de algemene trends die we eerder zichtbaar maakten.
# Vat de posterior voorspellingen van Y samen:colMeans(binary_prediction)
1 2 3 4
0.28045 0.80460 0.14825 0.65085
Deze voorspellingen geven meer inzicht in de verbanden tussen leeftijd, zuurstof, en succes. Bijvoorbeeld, onze posterior voorspelling is dat klimmer 1, die 20 jaar oud is en niet van plan is om zuurstof te gebruiken, 27.88% kans heeft om de top te halen. Deze kans is natuurlijk lager dan voor klimmer 2, die ook 20 is maar wel van plan is om zuurstof te gebruiken. Het is hoger dan de posterior voorspelling van succes voor klimmer 3, die ook niet van plan is zuurstof te gebruiken maar wel 60 jaar oud is. Over het algemeen is de voorspelling van succes het hoogst voor klimmer 2, die jonger is en van plan is zuurstof te gebruiken, en het laagst voor klimmer 3, die ouder is en niet van plan is zuurstof te gebruiken.
Posterior kans voorspellingen kunnen omgezet worden in posterior classificaties van binaire uitkomsten: ja of nee, verwachtingen of de klimmer zal slagen of niet? Als we een eenvoudige cut-off van 0,5 zouden gebruiken om dit te bepalen, dan zouden we klimmers 1 en 3 aanraden niet aan de expeditie deel te nemen (tenminste, niet zonder zuurstof) en klimmers 2 en 4 het groene licht geven. Maar in deze specifieke context moeten we het waarschijnlijk aan de individuele klimmers overlaten om hun eigen resultaten te interpreteren en hun eigen ja-of-nee beslissingen te nemen over het al dan niet voortzetten van hun expeditie. Zo kan een kans op succes van 65,16% voor sommigen de moeite en het risico waard zijn, maar voor anderen niet.
Model evaluatie
Om onze klimanalyse af te ronden, vragen we ons af: Is ons hiërarchisch-logistisch model een goed model? Lang verhaal kort, het antwoord is ja. - Ten eerste, ons model is eerlijk. De gegevens die we hebben gebruikt zijn openbaar en we verwachten niet dat onze analyse een negatief effect zal hebben op individuen of de samenleving. (Nogmaals, saaie antwoorden op de vraag naar eerlijkheid zijn de beste soort.)
- Ten tweede Posterior Predictive Checque controle toonde aan dat ons model niet al te verkeerd lijkt - onze posterior gesimuleerde succespercentages schommelen rond de waargenomen succespercentages in onze gegevens.
- Tenslotte, voor de vraag naar posterior classificatie nauwkeurigheid, kunnen we onze posterior classificaties van succes vergelijken met de werkelijke uitkomsten voor de 2076 klimmers in onze dataset. Standaard beginnen we met een kans cut-off van 0.5 - als de kans op succes van een klimmer groter is dan 0.5, voorspellen we dat hij zal slagen. We implementeren en evalueren deze classificatieregel met classification_summary() hieronder.
set.seed(84735)classification_summary(data = climbers, model = climb_model, cutoff =0.5)
In het algemeen voorspelt ons model met deze classificatieregel de resultaten goed voor 91,61% van onze klimmers. Dit ziet er behoorlijk fantastisch uit gezien het feit dat we enkel informatie gebruiken over de leeftijd en het zuurstofverbruik van de klimmers (terwijl er nog andere voorspellers te bedenken zijn (bv. bestemming, seizoen, enz.). Maar gezien de gevolgen van een foute classificatie in deze specifieke context (bv. risico op verwondingen), moeten we voorrang geven aan specificiteit, ons vermogen om te anticiperen wanneer een klimmer niet zou slagen. Om dit te bereiken voorspelde ons model slechts 92.51% van de mislukte beklimmingen correct. Om dit percentage te verhogen, kunnen we de waarschijnlijkheidsgrens in onze classificatieregel aanpassen.
In het algemeen kunnen we, om de specificiteit te verhogen, de waarschijnlijkheidsdrempel verhogen, waardoor het moeilijker wordt om “succes” te voorspellen. Na wat trial and error lijkt het erop dat cut-offs van ruwweg 0.65 of hoger een gewenst specificiteitsniveau van 95% zullen bereiken. Deze overschakeling naar 0.65 verlaagt natuurlijk de gevoeligheid van onze posterior classificaties, van 90.46% naar 81.54%, en dus ons vermogen om te detecteren wanneer een klimmer succesvol zal zijn. Wij denken dat de extra voorzichtigheid hier van belang is.
set.seed(84735)classification_summary(data = climbers, model = climb_model, cutoff =0.65)
Fast, Shannon, and Thomas Hegland. 2011. “Book Challenges: A Statistical Examination.” Project for Statistics 316-Advanced Statistical Modeling, St. Olaf College.
Legler, Julie, and Paul Roback. 2021. Beyond Multiple Linear Regression: Applied Generalized Linear Models and Multilevel Models in R. Chapman; Hall/CRC. https://bookdown.org/roback/bookdown-BeyondMLR/. ———. 2020b. “Himalayan Climbing Expeditions.” TidyTuesday Github Repostitory. https://github.com/rfordatascience/tidytuesday/tree/master/data/2020/2020-09-22.
The Himalayan Database. 2020. https://www.himalayandatabase.com/. Trinh, Ly, and Pony Ameri. 2016. “AirBnB Price Determinants: A Multilevel Modeling Approach.” Project for Statistics 316-Advanced Statistical Modeling, St. Olaf College.