library(sf)Warning: package 'sf' was built under R version 4.1.3Linking to GEOS 3.9.1, GDAL 3.2.1, PROJ 7.2.1; sf_use_s2() is TRUEchi_map <- read_sf("https://raw.githubusercontent.com/thisisdaryn/data/master/geo/chicago/Comm_Areas.geojson") Een instructieve handleiding op het maken van kaart is van de hand van Daryn Ramsden, die deze handleiding schreef om te laten zien hoe je dit met de R-pakketten ‘ggplot’(en sf) kunt doen. Hij doet dat van de stad Chicago met z’n communities. Ook hij koppelt deze geografische data aan aanvullende informatie.Ook Daryn bedankt.
Dit deel, schrijft Daryn, gaat over het gebruik van het ggplot2-pakket om eenvoudige kaarten te maken met behulp van R. Alle nodige invoergegevens zijn toegankelijk op hier.
Hij heeft ontdekt dat ggplot2 een toegankelijke ingang is voor het maken van kaarten in R: ggplot2 is een makkelijke datavisualisatieoplossing in het algemeen en het maken van kaarten met ggplot2 vereist relatief weinig nieuwe kennis om aan de slag te gaan met het maken van eenvoudige kaarten.
Hieronder gaat het niet om principes van goede cartografie. De kaarten worden in deze blog in de eerste plaats gemaakt om de functionaliteit van de gebruikte pakketten te demonstreren. Hij raadt iedereen die kaarten publiceert voor publieke consumptie aan om meer na te denken over de technische keuzes die gemaakt worden, bv. de keuze van schalen, dan deze post demonstreert.
sf pakketHet sf pakket is een sleutel tot het eenvoudig maken van kaarten met behulp van ggplot2. De naam van het pakket is afgeleid van simple features, een gestandaardiseerde manier om ruimtelijke vectorgegevens te coderen.
De code hieronder gebruikt sf::read_sf om vector data in te lezen in GeoJSON formaat. Dit GeoJSON bestand is afkomstig van de Chicago Data Portal en bevat de grenzen van 77 geïdentificeerde communities in de stad Chicago, Illinois.
library(sf)Warning: package 'sf' was built under R version 4.1.3Linking to GEOS 3.9.1, GDAL 3.2.1, PROJ 7.2.1; sf_use_s2() is TRUEchi_map <- read_sf("https://raw.githubusercontent.com/thisisdaryn/data/master/geo/chicago/Comm_Areas.geojson") Een blik op het chi_map object laat zien dat het lijkt op een typisch dataframe, misschien met een paar uitzonderingen: er is een begrenzingskader, bbox, wat tekst, proj4string die het gebruikte project aangeeft, en een geometry variabele die lengte- en breedtecoördinaten lijkt te bevatten. (De schermafbeelding hieronder is het resultaat van het uitvoeren van de head functie met chi_map als invoer op mijn eigen machine).
head(chi_map)Simple feature collection with 6 features and 9 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -87.7069 ymin: 41.79448 xmax: -87.58001 ymax: 41.99076
Geodetic CRS: WGS 84
# A tibble: 6 x 10
community area shape_~1 perim~2 area_~3 area_~4 comar~5 comarea shape~6
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 DOUGLAS 0 4600462~ 0 35 35 0 0 31027.~
2 OAKLAND 0 1691396~ 0 36 36 0 0 19565.~
3 FULLER PARK 0 1991670~ 0 37 37 0 0 25339.~
4 GRAND BOULEVARD 0 4849250~ 0 38 38 0 0 28196.~
5 KENWOOD 0 2907174~ 0 39 39 0 0 23325.~
6 LINCOLN SQUARE 0 7135232~ 0 4 4 0 0 36624.~
# ... with 1 more variable: geometry <MULTIPOLYGON [°]>, and abbreviated
# variable names 1: shape_area, 2: perimeter, 3: area_num_1, 4: area_numbe,
# 5: comarea_id, 6: shape_lenHier zien we de top van het sf-object ingelezen uit een GeoJSON bestand.
Als alternatief hadden wij de gegevens kunnen inlezen van een shapefile die de equivalente geospatiale informatie bevat. Shapefiles zijn een industrie-standaard, zeer algemeen bestandsformaat, en het is aannemelijk dat dit het formaat is waarmee de gegevens waarmee je wilt werken het gemakkelijkst gedistribueerd worden.
De github repository bevat ook een shapefile directory, Comm_Areas_shp met gelijkwaardige geospatiale informatie die ook verkregen werd via de Chicago Data Portal.
ggplot2 met geom_sfDe sleutel tot het gebruik van ggplot2 om kaarten te maken met sf objecten is dat ze ook dataframes zijn en dus in principe klaar om gebruikt te worden als data voor ggplot2::ggplot.
We kunnen een eerste kaart maken door ons kaart-dataframe te gebruiken als data-input voor ggplot2::ggplot en door gebruik te maken van een speciale geometrie, ggplot2::geom_sf:
library(ggplot2)Warning: package 'ggplot2' was built under R version 4.1.3ggplot(data = chi_map) + geom_sf()
Een andere handige geometrie die ons in staat stelt om vrij eenvoudig informatie aan kaarten toe te voegen is ggplot2::geom_sf_text. In de onderstaande code gebruiken we deze geometrie om het aantal identificatienummers van elk gebied in de Chicago gemeenschap toe te voegen aan de eenvoudige kaart.
ggplot(data = chi_map) +
geom_sf() +
geom_sf_text(aes(label = area_num_1))Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
give correct results for longitude/latitude data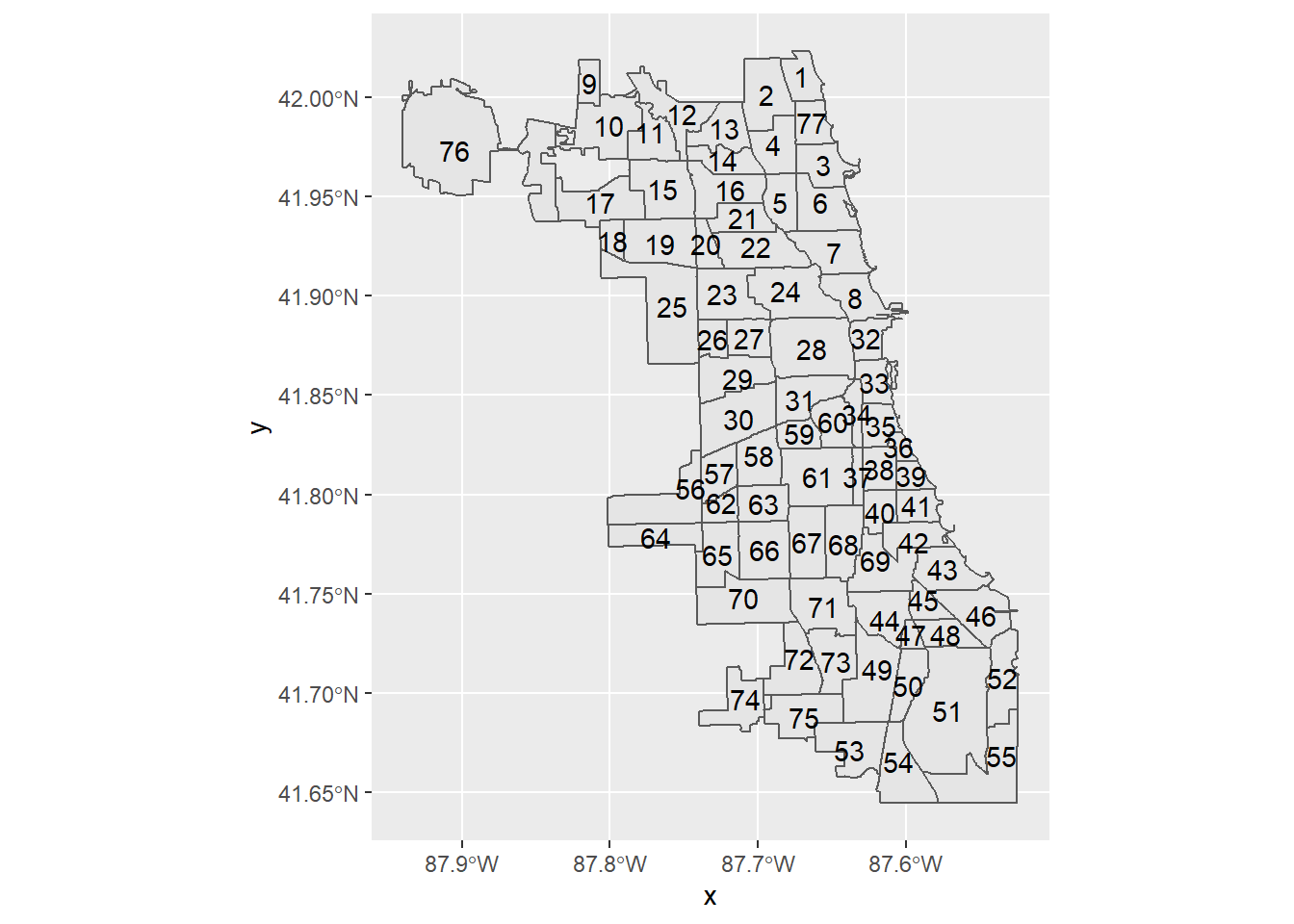
We kunnen het thema van een kaart veranderen, net als met elke andere ggplot2 grafiek. Bijvoorbeeld, hier is de vorige kaart met een extra oproep aan ggplot2::theme_bw om een zwart-wit thema te krijgen.
ggplot(data = chi_map) +
geom_sf() +
geom_sf_text(aes(label = area_num_1)) +
theme_bw()Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
give correct results for longitude/latitude data
Om chloropleth-kaarten te maken, moeten we andere informatie verkrijgen die overeenstemt met de geografische gebieden die in de kaart worden afgebakend.
Chicago Open Data heeft een dataset van Publieke Gezondheidsstatistiek voor communities. Dit is een goede databron om te gebruiken om chloropleth kaarten te maken in combinatie met de geospatiale gegevens.
library(readr)Warning: package 'readr' was built under R version 4.1.3chi_health <- read_csv("https://raw.githubusercontent.com/thisisdaryn/data/master/geo/chicago/Chicago_Health_Statistics.csv") Rows: 77 Columns: 29
-- Column specification --------------------------------------------------------
Delimiter: ","
chr (2): Community Area Name, Gonorrhea in Males
dbl (27): Community Area, Birth Rate, General Fertility Rate, Low Birth Weig...
i Use `spec()` to retrieve the full column specification for this data.
i Specify the column types or set `show_col_types = FALSE` to quiet this message.head(chi_health)# A tibble: 6 x 29
Community Ar~1 Commu~2 Birth~3 Gener~4 Low B~5 Prena~6 Prete~7 Teen ~8 Assau~9
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 Rogers~ 16.4 62 11 73 11.2 40.8 7.7
2 2 West R~ 17.3 83.3 8.1 71.1 8.3 29.9 5.8
3 3 Uptown 13.1 50.5 8.3 77.7 10.3 35.1 5.4
4 4 Lincol~ 17.1 61 8.1 80.5 9.7 38.4 5
5 5 North ~ 22.4 76.2 9.1 80.4 9.8 8.4 1
6 6 Lake V~ 13.5 38.7 6.3 79.1 8.1 15.8 1.4
# ... with 20 more variables: `Breast cancer in females` <dbl>,
# `Cancer (All Sites)` <dbl>, `Colorectal Cancer` <dbl>,
# `Diabetes-related` <dbl>, `Firearm-related` <dbl>,
# `Infant Mortality Rate` <dbl>, `Lung Cancer` <dbl>,
# `Prostate Cancer in Males` <dbl>, `Stroke (Cerebrovascular Disease)` <dbl>,
# `Childhood Blood Lead Level Screening` <dbl>,
# `Childhood Lead Poisoning` <dbl>, `Gonorrhea in Females` <dbl>, ...In dit bestand zijn de identificaties van communities numerieke variabelen. Om de twee databestanden (chi_map en Chi_health) te kunnen samenvoegen, moet een nieuwe kolom, area_num_1, worden aangemaakt als tekst/karakterdata. (Door dezelfde naam, area_num_1, te gebruiken die reeds in het chi_map data frame staat, wordt het samenvoegen bijzonder gemakkelijk.).
library(dplyr)Warning: package 'dplyr' was built under R version 4.1.3
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionchi_health <- chi_health %>%
mutate(area_num_1 = as.character(`Community Area`))sf-object met een ander dataframeVervolgens, gebruik dplyr::left_join om chi_map te verbinden met chi_health:
chi_health_map <- left_join(chi_map, chi_health, by = "area_num_1")Dit creëert een enkel dataframe met de geografische grenzen en de waarden voor de gemeten variabelen.
Om een chloropleth-kaart te maken met behulp van een van de statistieken in het samengevoegde dataframe, kunnen we de fill aesthetic gebruiken. Hier gebruiken we de kolom “Unemployment” van de samengevoegde gegevens:
chi_health_map_nl<-chi_health_map %>%
rename(Werkloosheid=Unemployment) ggplot(data = chi_health_map_nl, aes(fill = Werkloosheid)) +
geom_sf() +
ggtitle("Werkloosheidspercentages in de communities van Chicago")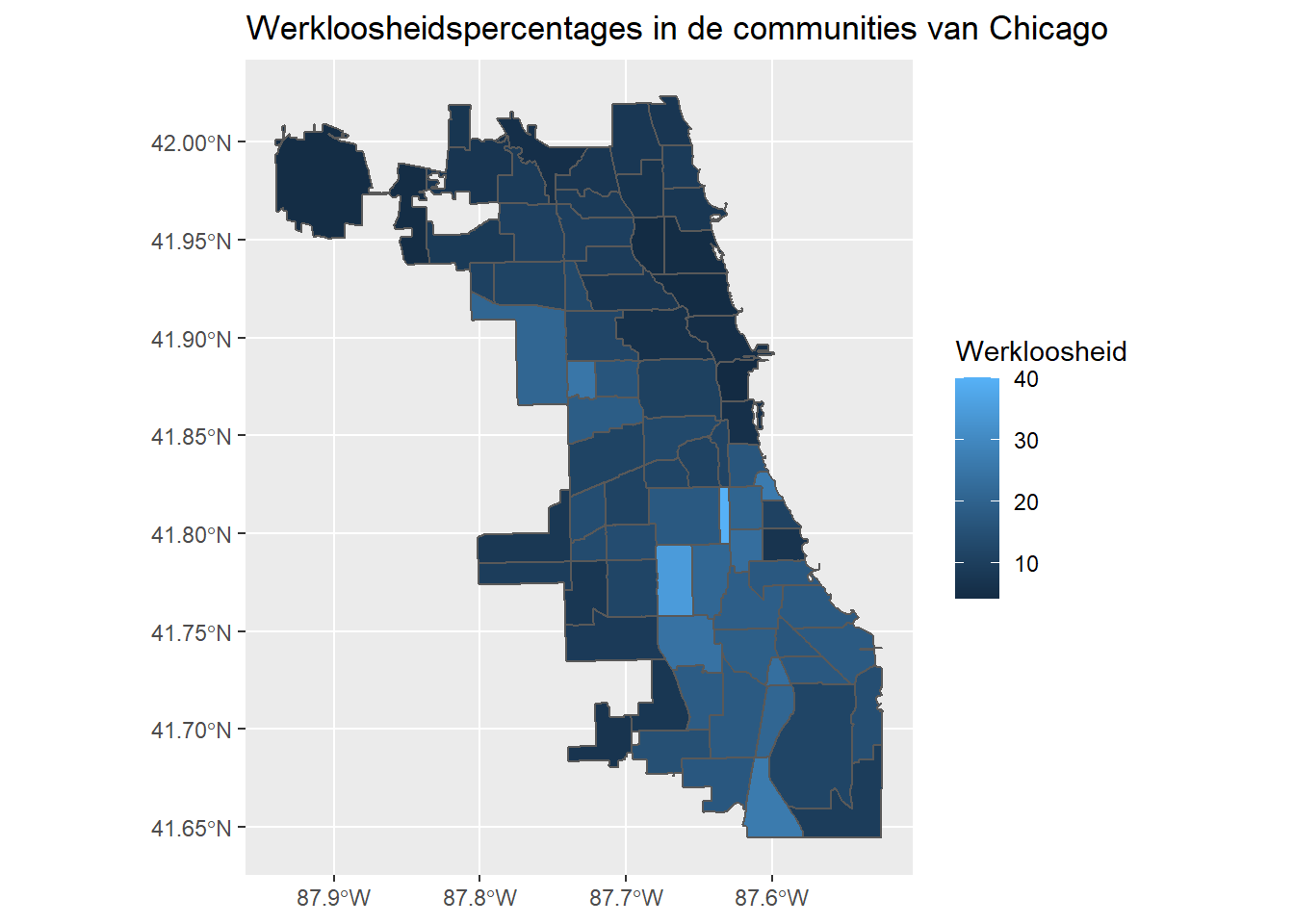
De vorige kaart gebruikt de standaard continue schaal voor de vulling esthetiek. Merk op dat we dezelfde kaart kunnen maken als voorheen door scale_fill_continuous te gebruiken:
ggplot(data = chi_health_map_nl, aes(fill = Werkloosheid)) +
geom_sf() +
scale_fill_continuous() +
ggtitle("Werkloosheidpercentages in communities van Chicago")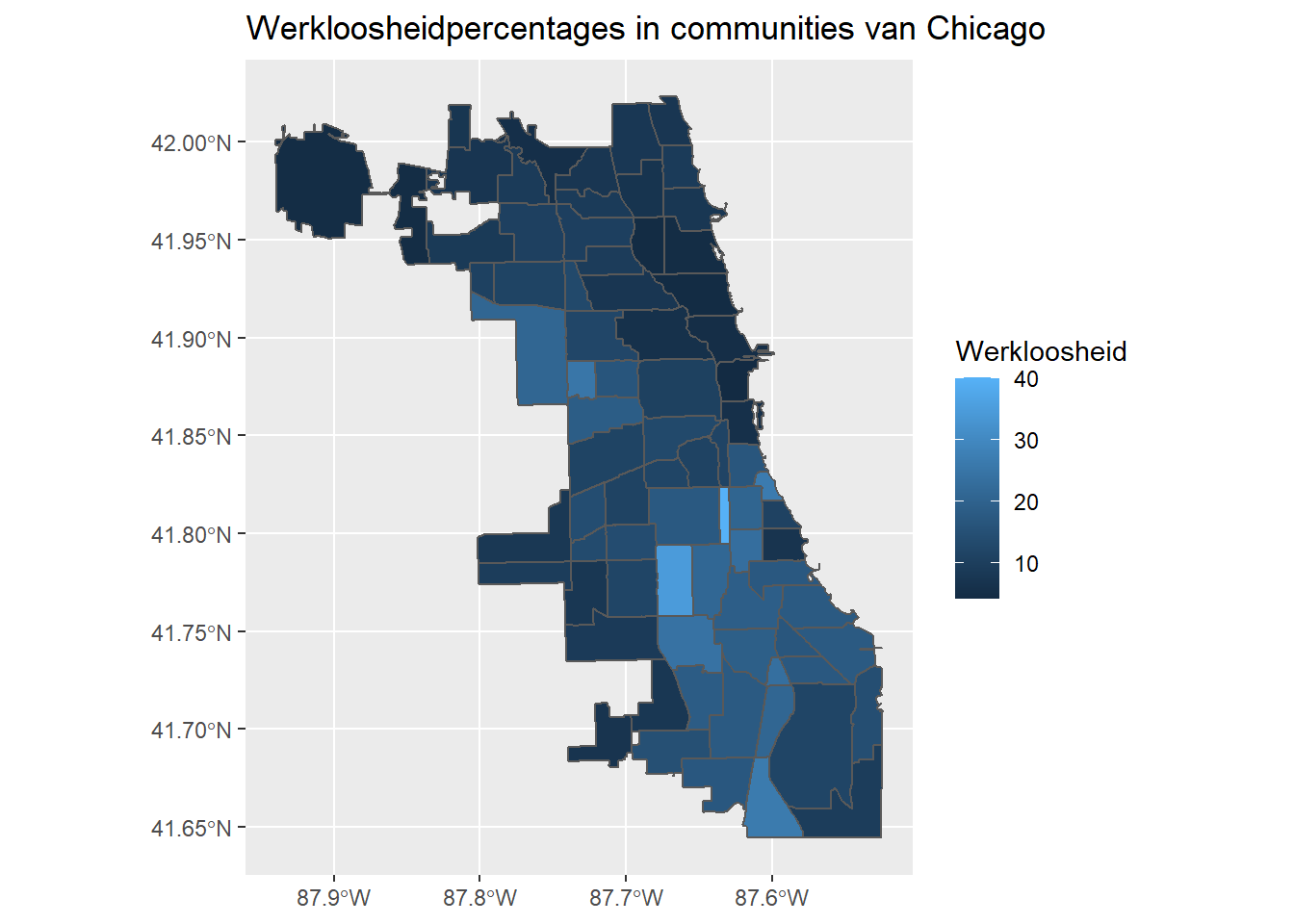
We kunnen viridis scale als alternatief gebruiken die ook beschikbaar is voor scale_fill_continuous:
ggplot(data = chi_health_map_nl, aes(fill = Werkloosheid)) +
geom_sf() +
scale_fill_continuous(type = "viridis") +
ggtitle("Werkloosheidsperscentages in communities van Chicago")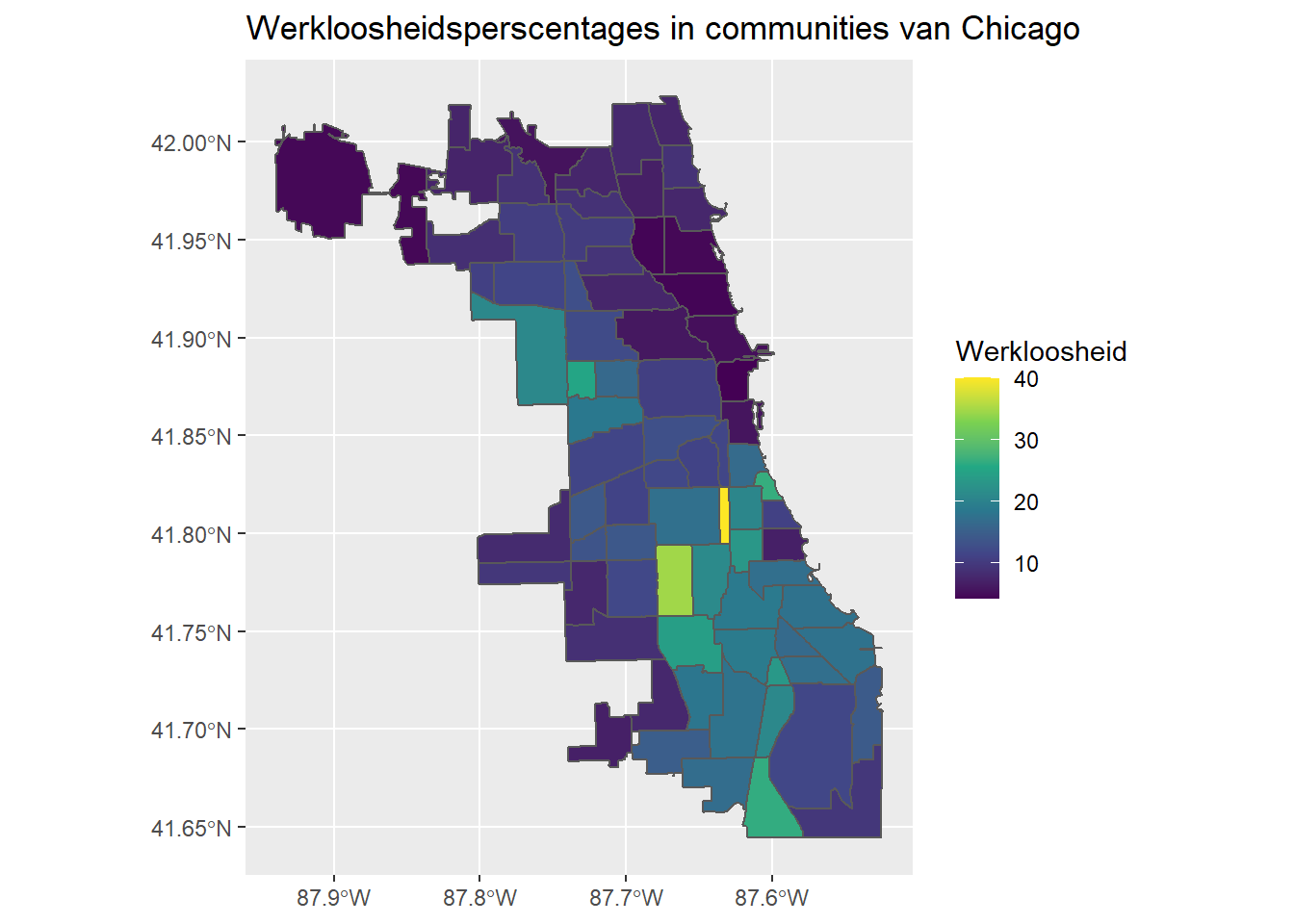
Een andere optie is met de hand instellen van laag and hoog argumenten voor scale_fill_continuous.
ggplot(data = chi_health_map_nl, aes(fill = Werkloosheid)) +
geom_sf() +
scale_fill_continuous(low = "ivory", high = "brown") +
ggtitle("Werkloosheidspercentages in communities van Chicago")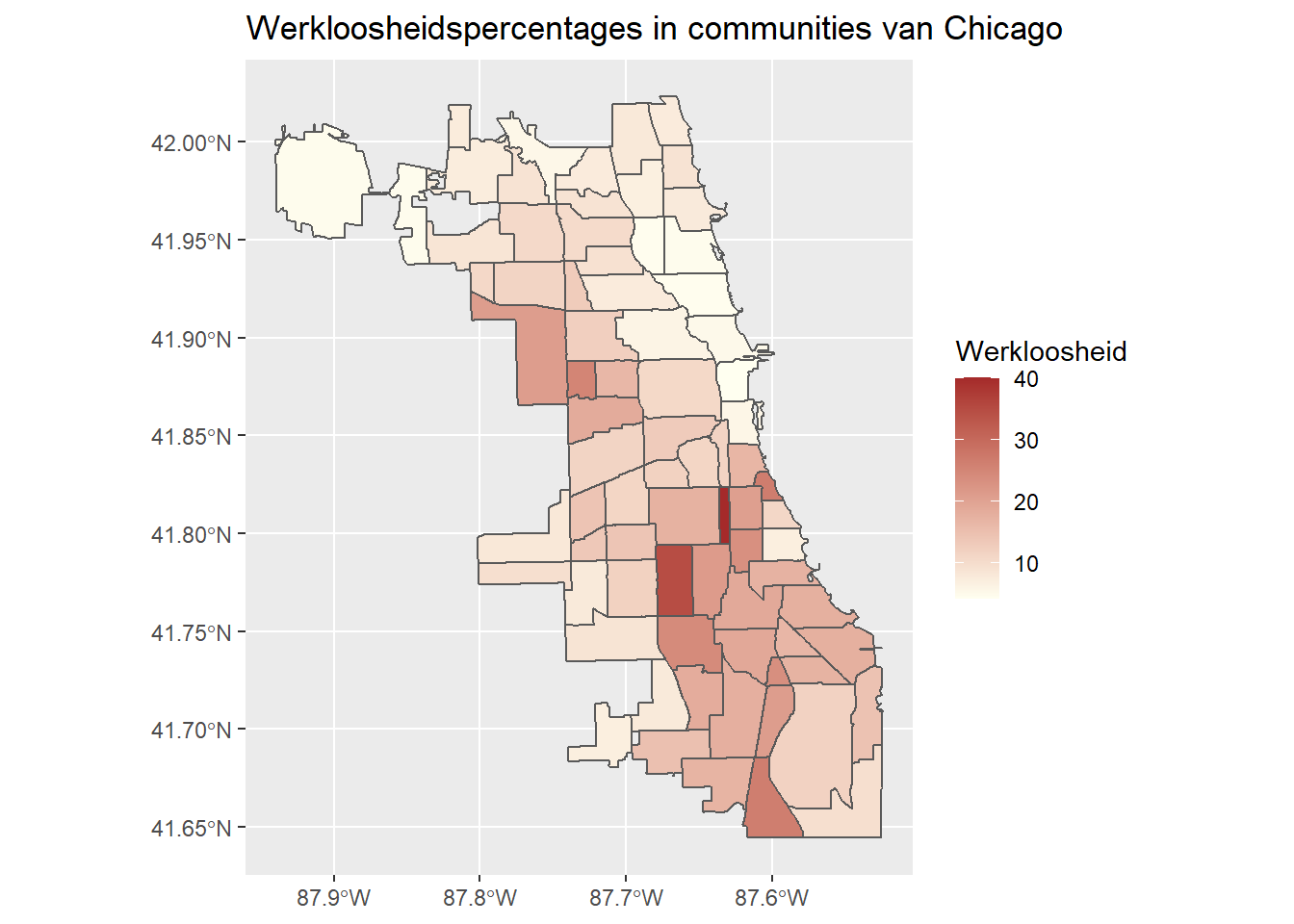
Misschien wil je wel een divergente schaal gebruiken:
Om een divergerende - maar nog steeds continue schaal te krijgen - kun je ggplot2::scale_fill_gradient2 gebruiken. Om deze schaal te gebruiken, stelt je kleuren in voor de argumenten low, high en mid. Het kan zijn dat u ook het midpoint argument moet instellen (dat anders standaard op 0 zou worden gezet).
ggplot(data = chi_health_map_nl, aes(fill = Werkloosheid)) +
geom_sf() +
scale_fill_gradient2(low = "blue", mid = "white", high = "red", midpoint = 20) +
ggtitle("Werkloosheidspercentages in communities van Chicago")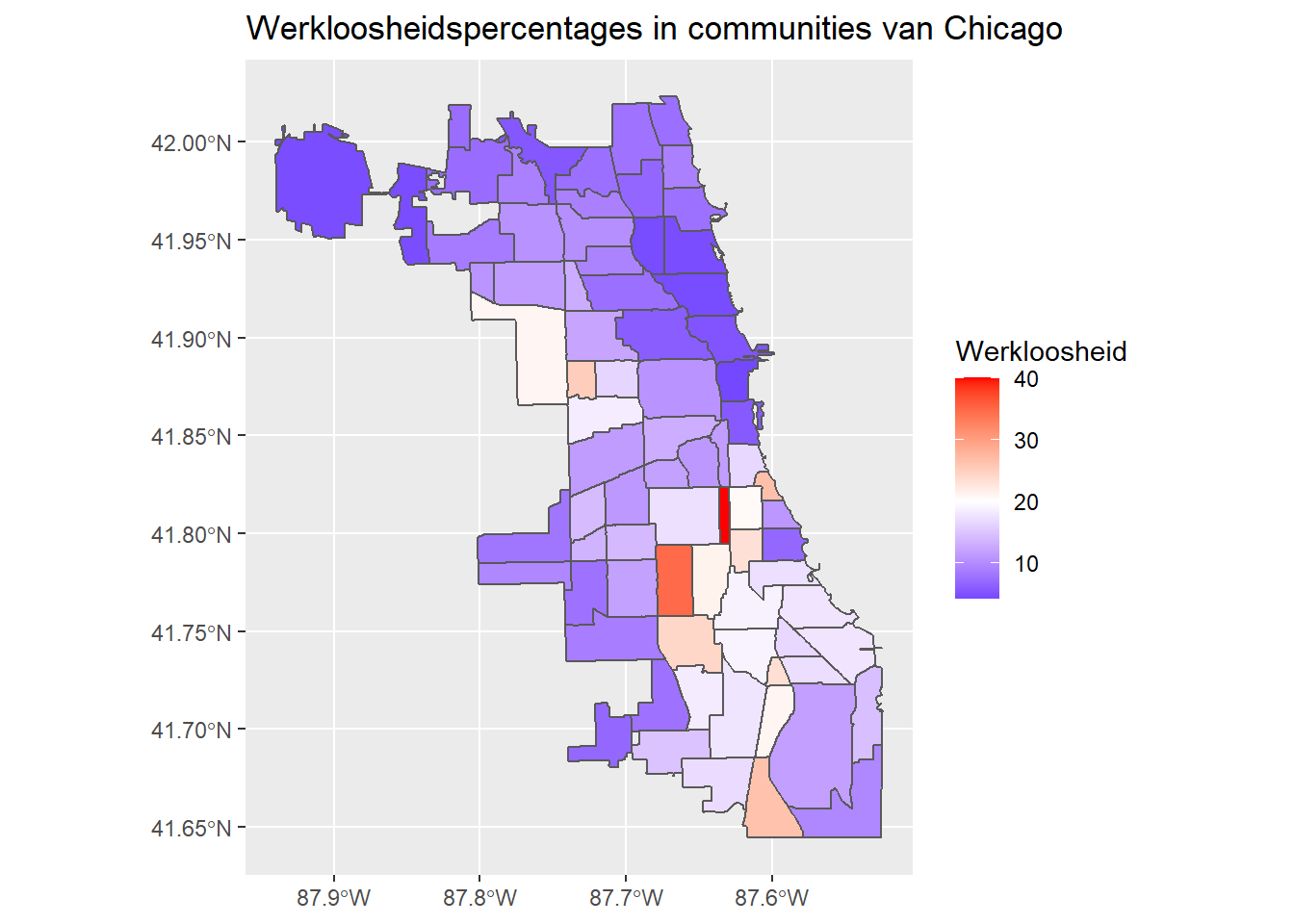
Tot nu toe hebben we continue schalen gebruikt om de communities van de chloroplethkaarten in te kleuren. Dit is een gevolg van het gebruik van een numerieke variabele als onze fill aes. Als alternatief kunnen we een discrete schaal gebruiken door de fill toe te wijzen aan een categorische variabele.
Maak eerst een nieuwe categorische variabele voor Werkloosheid - of een andere variabele in de gegevens van uw keuze. De code gebruikt dplyr::case_when om de variabele Werkloosheid in bereiken te verdelen:
chi_health_map_nl <- chi_health_map_nl %>%
mutate(Werkl_cat = case_when(
Werkloosheid <= 10 ~ "0 - 10",
10 < Werkloosheid & Werkloosheid <= 20 ~ "10+ - 20",
20 < Werkloosheid & Werkloosheid <= 30 ~ "20+ - 30",
30 < Werkloosheid ~ "30+"))Now, plot the new map:
ggplot(data = chi_health_map_nl) +
geom_sf(aes(fill = Werkl_cat)) +
labs(fill = "Werkloosheid (%)") +
ggtitle("Werkloosheidspercentages in communities van Chicago")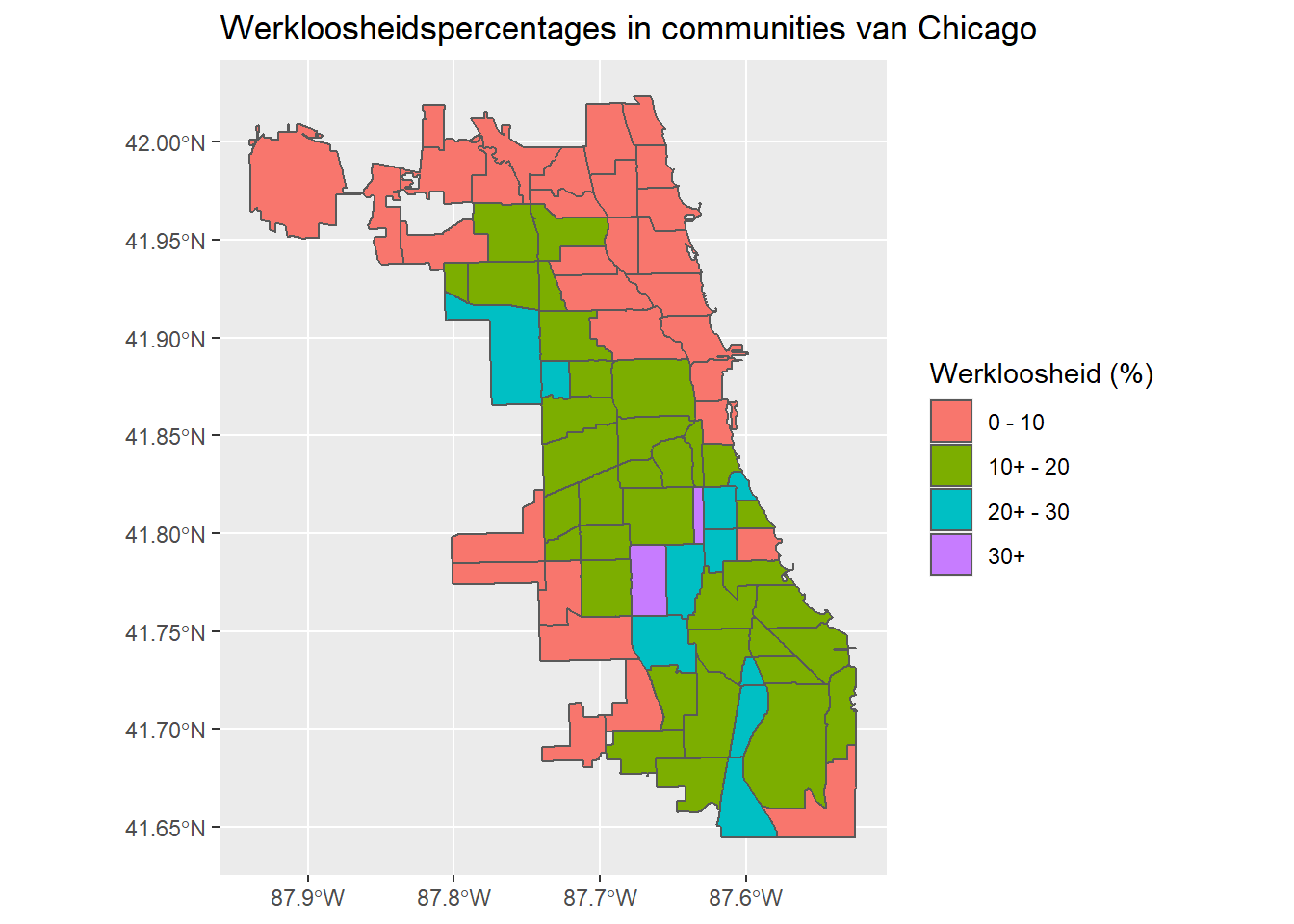
Om een voorbeeld te geven van het plotten van punten op een kaart, kunnen we gebruik maken van Chicago Restaurant Inspectie Data voor februari 2020. Lees eerst de gegevens in:
inspections <- read_csv("https://raw.githubusercontent.com/thisisdaryn/data/master/geo/chicago/Food_Inspections.csv")Rows: 950 Columns: 17
-- Column specification --------------------------------------------------------
Delimiter: ","
chr (12): DBA Name, AKA Name, Facility Type, Risk, Address, City, State, Ins...
dbl (5): Inspection ID, License #, Zip, Latitude, Longitude
i Use `spec()` to retrieve the full column specification for this data.
i Specify the column types or set `show_col_types = FALSE` to quiet this message.Deze dataset heeft de volgende variabelen: - Inspection
- ID,
- DBA
- Name,
- AKA,
- Name,
- License #,
- Facility
- Type,
- Risk,
- Address,
- City,
- State,
- Zip,
- Inspection Date,
- Inspection
- Type,
- Results,
- Violations,
- Latitude,
- Longitude, and
- Location.
Nu kunnen we elk geïnspecteerd restaurant in de tijdsperiode op de kaart plaatsen door de x en y aes te koppelen aan de Longitude en Latitude variabelen in het dataframe. (Bovendien, de code hieronder mapt de kleur aes aan de Results variabele).
ggplot() +
geom_sf(data = chi_map, fill = "ivory", colour = "ivory") +
geom_point(data = inspections, aes(x = Longitude, y = Latitude, colour = Results)) +
scale_color_viridis_d()Warning: Removed 4 rows containing missing values (geom_point).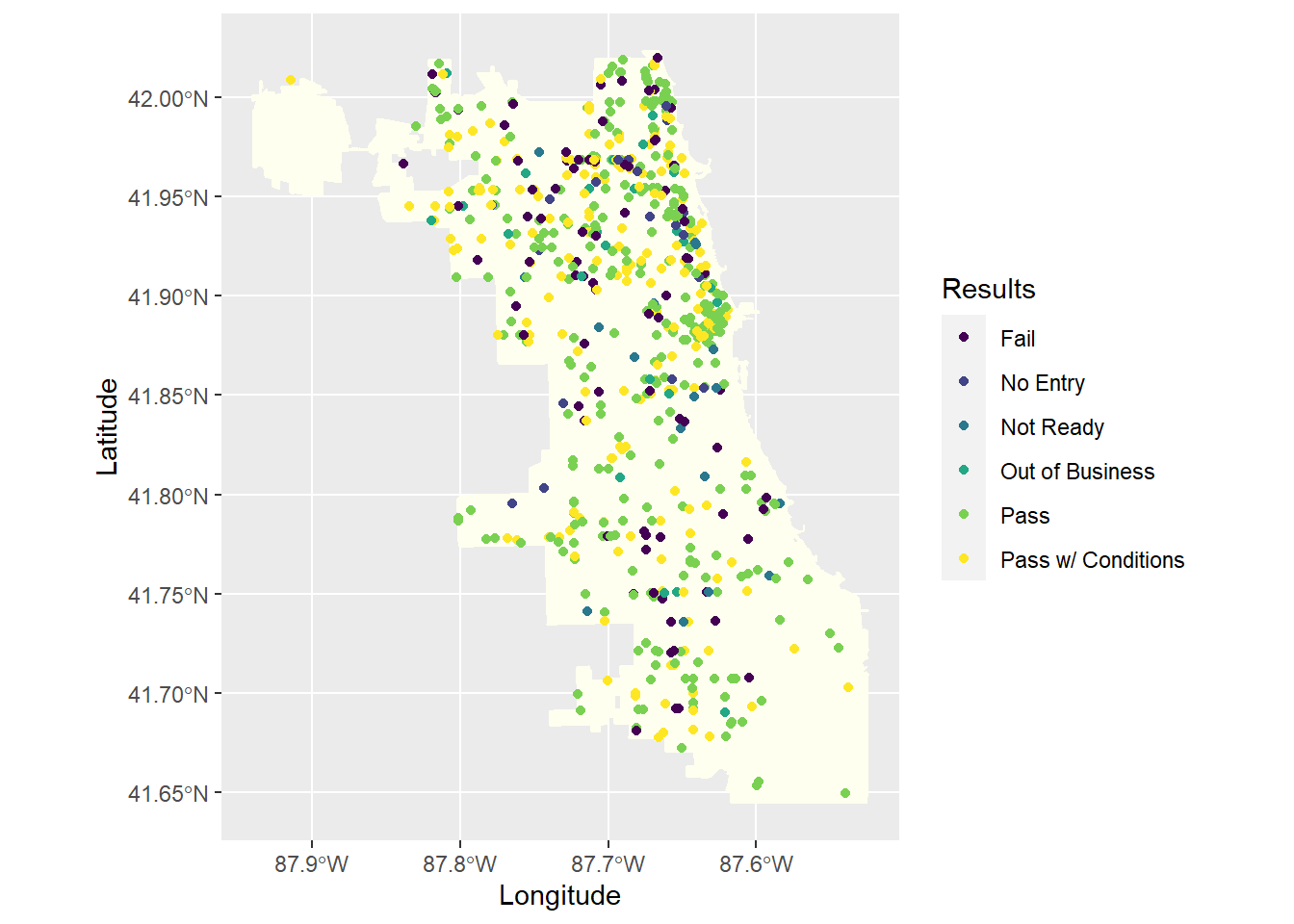
plotlyHet maken van interactieve kaarten met plotly kan ook relatief eenvoudig zijn. In de onderstaande code voeren we de volgende stappen uit:
desc met daarin de Restaurantnaam, de inspectiedatum en het resultaat van de inspectie aan de hand van de corresponderende variabelen in de gegevens.plotly::ggplotly met de desc variabele als tooltiplibrary(plotly)
Attaching package: 'plotly'The following object is masked from 'package:ggplot2':
last_plotThe following object is masked from 'package:stats':
filterThe following object is masked from 'package:graphics':
layoutinspections <- inspections %>% mutate(desc = paste(`AKA Name`, `Inspection Date`, Results, sep = "\n"))
insp_plt <- ggplot() +
geom_sf(data = chi_map, fill = "ivory", colour = "ivory") +
geom_point(data = inspections,
aes(x = Longitude, y = Latitude, colour = Results, text = desc)) +
scale_color_viridis_d()Warning: Ignoring unknown aesthetics: textggplotly(insp_plt, tooltip = "desc")