Dit is een blog naar aanleiding van Gelman/Hill/Vehtari nieuwe boek Regresion and other stories
analyse
Author
Harrie Jonkman
Published
February 10, 2022
Regression and other stories
Vijftien jaar geleden schreven Gelman en Hill Data analysis using regression and multilevel/hierarchical models, een klassieker over moderne data-analyse. Ze gebruikte R en WinBugs voor lineaire en logistische, hierarchische regressieanalyse en causale inferentie. Ze lieten zien hoe je dat op de frequentistische en Bayesiaanse manier kunt doen. Het boek werd voor mij een naslagwerk dat ik steeds maar weer uit de kast trok. Vorig jaar dacht ik, laat ik eens zien of Gelman al weer iets nieuws heeft geschreven en toen zag ik dat Regression and other storieshiernet uit was is. Dat heeft Andrew Gelman weer met Jennifer Hill geschreven maar nu ook met de Fin Aki Vehtari. Ik was er nog niet aan toe gekomen om het te lezen. Dat heb ik deze maand gedaan. Ook dit boek zal ik vaker uit de kast trekken. Dit boek gaat over allerlei aspecten van regressie. Het is een theoretisch én praktisch boek. Je leert, wat ze noemen, voorspellende modellen beter begrijpen, toepassen in verschillende praktische problemen en je leert het simuleren. Je leert het opbouwen vanaf de basis en daarna kun je het in verschillende situaties toepassen. Het wil kritisch zijn, zonder nihilistisch te worden en vooral laten zien dat je van statistische analyse kunt leren. Ook dit boek staat op twee benen: frequentisch en Bayesiaans en laat zien hoe informatie wordt gebruikt in het schattingsproces, de assumpties die eraan ten grondslag liggen en hoe schattingen en voorspellingen kunnen worden geïnterpreteerd in beide raamwerken. Beide kunnen worden gebruikt, maar het is ook duidelijk dat de voorkeur bij Bayesiaanse benadering ligt. Dan kun je ook andere informatie gebruiken om te schatten of te voorspellen. En omdat je simuleert (het model duizenden keren draait) kunt je met de Bayesiaanse techniek meer zeggen over onzekerheid. Dat maakt deze techniek zeer geschikt voor regressieanalyses zoals in dit boek gepresenteerd. Wat ik zelf van dit boek heb geleerd zijn de mogelijkheden om op basis van gegevens te voorspellen. Vooral hoofdstuk 9 (Voorspellen en Bayesiaanse inferentie) vond ik interessant. Maar het boek zit vol informatie en kennis en laat zich amper samenvatten. Het lijkt erop dat het een eerste deel is en ik verwacht dat er later nog een tweede deel komt dat de nadruk legt op multilevel analyse. We zullen zien Bij het boek zit ook nog een website met data en scripts om zelf uit te proberen, prachtig onderwijsmateriaal opgesteld door Aki Vehtari hier.
Interssante blog
Toen ik het boek uit had kwam ik een een blog tegen op R-bloggers. Het verscheen op 1 september 2021 hier, maar ik kon niet zien van wie het is (Mister X, sorry. Hij of zij schreef het nadat deze persoon Regression and other stories had gelezen. Het vat heel goed samen hoe moderne regressieanalyse werkt en daarom heb ik het voor hier vertaald.
# Eerst de pakketten inladen die we nodig hebbenlibrary(plyr); library(dplyr)
Warning: package 'plyr' was built under R version 4.1.3
Warning: package 'dplyr' was built under R version 4.1.3
Attaching package: 'dplyr'
The following objects are masked from 'package:plyr':
arrange, count, desc, failwith, id, mutate, rename, summarise,
summarize
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(rstanarm)
Warning: package 'rstanarm' was built under R version 4.1.3
Loading required package: Rcpp
Warning: package 'Rcpp' was built under R version 4.1.3
This is rstanarm version 2.21.3
- See https://mc-stan.org/rstanarm/articles/priors for changes to default priors!
- Default priors may change, so it's safest to specify priors, even if equivalent to the defaults.
- For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores())
library(bayesplot)
Warning: package 'bayesplot' was built under R version 4.1.3
This is bayesplot version 1.9.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
library(ggplot2)
Warning: package 'ggplot2' was built under R version 4.1.3
library(readr)
Warning: package 'readr' was built under R version 4.1.3
Bayesiaanse regressieanalyse met Rstanarm
In deze post zullen we een eenvoudig voorbeeld van Bayesiaanse regressieanalyse doornemen met het rstanarm pakket in R. Ik heb Gelman, Hill en Vehtari’s recente boek Regression and Other Stories” gelezen, en deze blog post is mijn poging om enkele van de dingen die ik heb geleerd toe te passen. Ik heb de afgelopen jaren stukjes en beetjes van de Bayesiaanse benadering opgevangen, en ik vind het een heel interessante manier om over gegevensanalyse na te denken en ze uit te voeren. Ik heb met veel plezier het nieuwe boek van Gelman en collega’s doorgewerkt en geëxperimenteerd met deze technieken, en ik ben blij dat ik hier iets kan delen van wat ik heb geleerd.
Je kunt de gegevens en alle code van deze blogpost hier op Github vinden.
De data
De gegevens die we in deze blog zullen onderzoeken bestaan uit de dagelijkse totale stappentellingen van verschillende fitnesstrackers die ik de afgelopen 6 jaar heb gehad. De eerste waarneming werd geregistreerd op 2015-03-04 en de laatste op 2021-03-15. Gedurende deze periode bevat de dataset de dagelijkse totale stappentellingen voor 2.181 dagen.
Naast de dagelijkse totale stappentelling bevat de dataset informatie over de dag van de week (bijv. maandag, dinsdag, etc.), het apparaat dat is gebruikt om de stappentelling vast te leggen (door de jaren heen heb ik er 3 gehad - Accupedo, Fitbit en Mi-Band), en het weer voor elke datum (de gemiddelde dagelijkse temperatuur in graden Celsius en de totale dagelijkse neerslag in millimeters, verkregen via het GSODR pakket in R).
De dataset (genaamd steps_weather) ziet er als volgt uit:
# Data inladenlibrary(readr)steps_weather <-read_csv("C:/FilesHarrie/Stanexample/Rstanarmexample/bayesian_regression_rstanarm/Data/steps_weather.csv")
Rows: 2181 Columns: 7
-- Column specification --------------------------------------------------------
Delimiter: ","
chr (3): dow, week_weekend, device
dbl (3): daily_total, temp, prcp
date (1): date
i Use `spec()` to retrieve the full column specification for this data.
i Specify the column types or set `show_col_types = FALSE` to quiet this message.
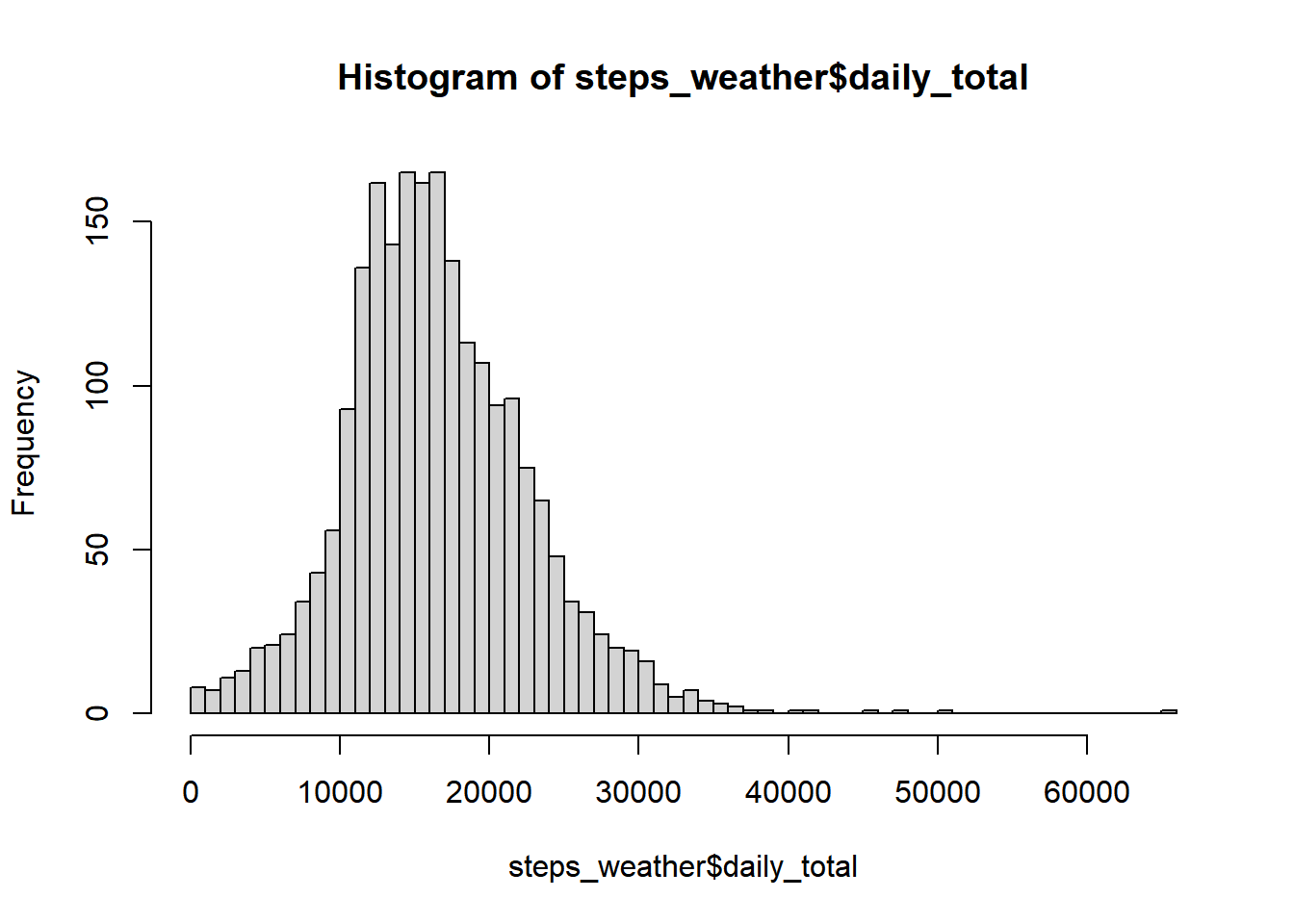
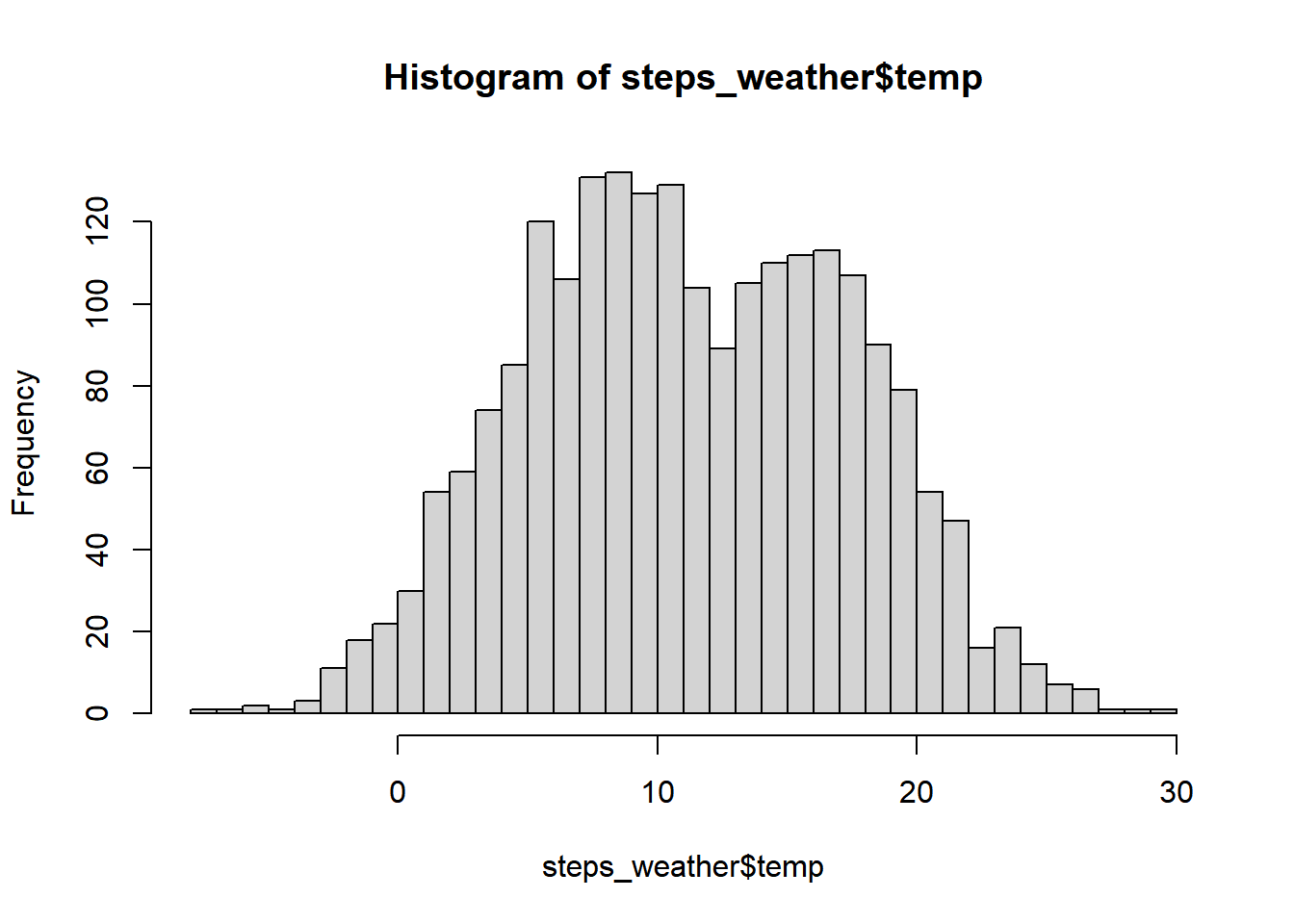
Hieronder zie je histogrammen van twee variabelen, namelijk dagelijks totale aantal stappen en de gemiddelde temperatuur over deze periode.
hist(steps_weather$daily_total, breaks =50)
hist(steps_weather$temp, breaks =50)
Regressie Analyse
Het doel van deze blogbijdrage is Bayesiaanse regressiemodellering te verkennen met behulp van het rstanarm pakket. Daarom zullen we de gegevens gebruiken om een zeer eenvoudig model te maken en ons te concentreren op het begrijpen van de modelfit en verschillende regressiediagnoses.
Ons model hier is een lineair regressiemodel dat de gemiddelde temperatuur in graden Celsius gebruikt om het totale dagelijkse aantal stappen te voorspellen. We gebruiken het stan_glm commando om de regressie-analyse uit te voeren. We kunnen het model uitvoeren en een samenvatting van de resultaten zien die de volgende tabel oplevert.
Het draait 4.000 iteraties en daarna worden de resultaten gepresenteerd.
fit_1 <-stan_glm(daily_total ~ temp, data = steps_weather)
Model Info:
function: stan_glm
family: gaussian [identity]
formula: daily_total ~ temp
algorithm: sampling
sample: 4000 (posterior sample size)
priors: see help('prior_summary')
observations: 2181
predictors: 2
Estimates:
mean sd 10% 50% 90%
(Intercept) 16218.9 276.0 15869.3 16215.8 16580.9
temp 26.6 21.0 -0.9 26.4 53.5
sigma 6199.8 96.4 6082.2 6198.2 6322.6
Fit Diagnostics:
mean sd 10% 50% 90%
mean_PPD 16519.2 190.8 16279.1 16518.9 16767.0
The mean_ppd is the sample average posterior predictive distribution of the outcome variable (for details see help('summary.stanreg')).
MCMC diagnostics
mcse Rhat n_eff
(Intercept) 4.3 1.0 4169
temp 0.3 1.0 4436
sigma 1.7 1.0 3317
mean_PPD 3.1 1.0 3896
log-posterior 0.0 1.0 1716
For each parameter, mcse is Monte Carlo standard error, n_eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor on split chains (at convergence Rhat=1).
Deze tabel bevat de volgende variabelen:
Intercept: Dit cijfer geeft het verwachte dagelijkse aantal stappen weer wanneer de gemiddelde dagtemperatuur 0 is. Met andere woorden, het model voorspelt dat, wanneer de gemiddelde dagtemperatuur 0 graden Celsius is, ik op die dag 16211,7 stappen zal lopen.
temp: Dit is de geschatte toename van het dagelijkse aantal stappen per 1 eenheid stijging van de gemiddelde dagelijkse temperatuur in graden Celsius. Met andere woorden, het model voorspelt dat voor elke 1 graad stijging van de gemiddelde dagtemperatuur, ik die dag 26,8 extra stappen zal zetten.
sigma: Dit is de geschatte standaardafwijking van de residuen van het regressiemodel. (Het residu is het verschil tussen de modelvoorspelling en de waargenomen waarde voor het dagelijkse totale aantal stappen). De verdeling van de residuele waarden heeft een standaardafwijking van 6195,1.
geman_PPD: De mean_ppd is de gemiddelde posterior predictive distributie van de door het model geïmpliceerde uitkomstvariabele (we zullen dit verder bespreken in het gedeelte over posterior predictive checques hieronder).
De uitvoer in de samenvattende tabel hierboven lijkt vrij veel op de uitvoer van een standaard gewone kleinste kwadratenregressie. In de Bayesiaanse benadering van regressiemodellering krijgen we echter niet gewoon puntschattingen van coëfficiënten, maar eerder volledige verdelingen van simulaties die mogelijke waarden van de coëfficiënten vertegenwoordigen, gegeven het model. Met andere woorden, de getallen in de bovenstaande tabel zijn gewoon samenvattingen van verdelingen van coëfficiënten die de relatie tussen de voorspellers en de uitkomstvariabele beschrijven.
Standaard geven de rstanarm regressiemodellen 4.000 simulaties van de posterior verdeling voor elke modelparameter. We kunnen de simulaties uit het modelobject halen en ze als volgt bekijken:
# extraheer de simulaties van het modelobjectsims <-as.matrix(fit_1)
En dat geeft 4000 posterior simulaties van de parameters intercept, temp en sd. Deze simulaties drukken de onzekerheid uit van de modeloutput die je hierboven vindt
De gemiddelde waarden van deze verdelingen van simulaties worden weergegeven in de hierboven afgebeelde tabel met regressiesamenvattingsuitvoer.
# gemiddelde en intercept - matchen met de tabel mean(sims[,1])
[1] 16218.87
sd(sims[,1])
[1] 275.9854
# gemiddelde en sd temp - matchen met de tabel mean(sims[,2])
[1] 26.62242
median(sims[,2])
[1] 26.44791
sd(sims[,2])
[1] 21.03643
# gemiddelde en sd sigma - matchen met de tabel mean(sims[,3])
[1] 6199.79
sd(sims[,3])
[1] 96.39904
Visualiseren van de posterior distributies met bayesplot
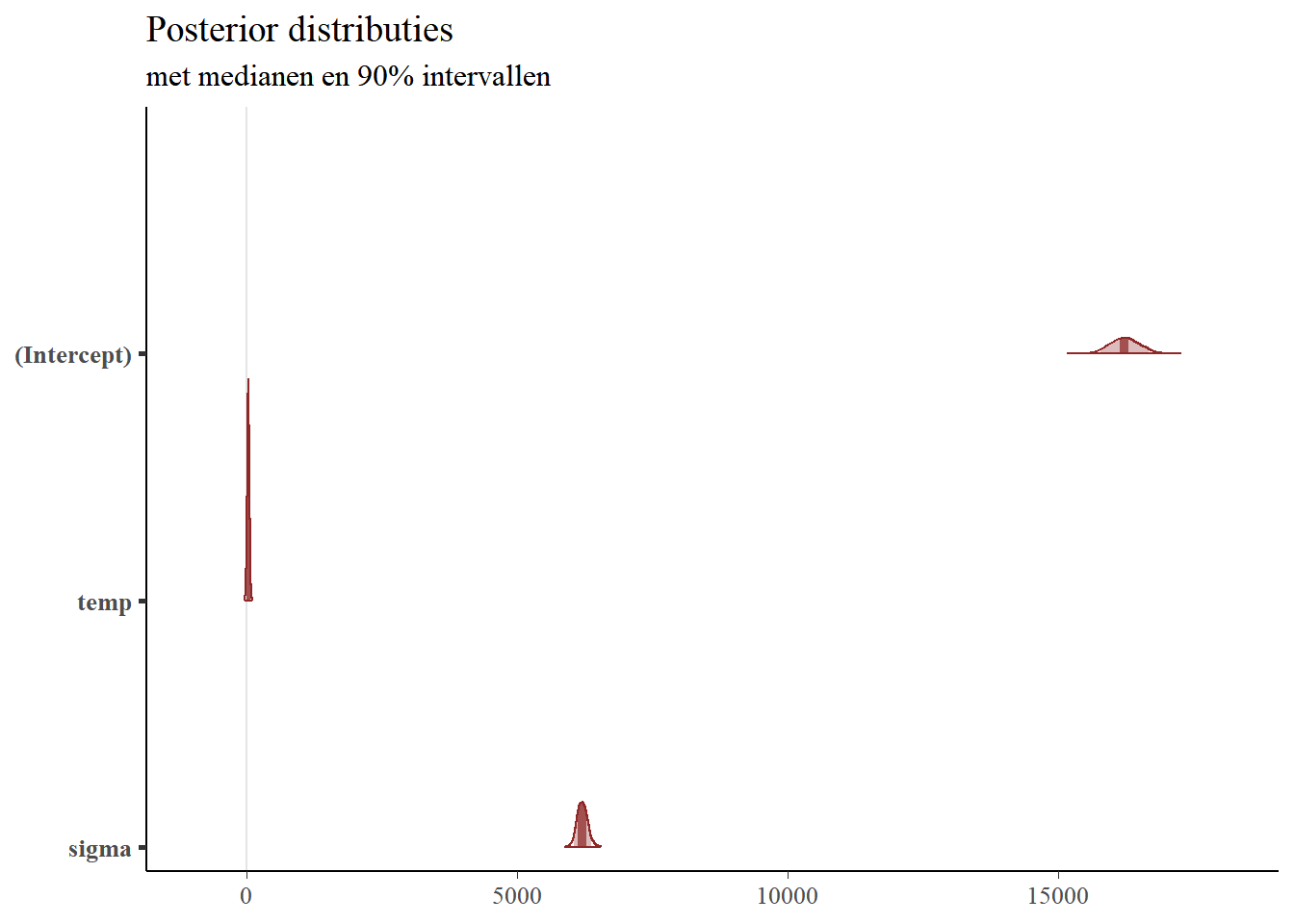
Het uitstekende bayesplot-pakket bevat een aantal handige functies om de posterior distributies van onze coëfficiënten te visualiseren. Laten we de mcmc_areas-functie gebruiken om de 90% geloofwaardige intervallen voor de modelcoëfficiënten weer te geven. die de volgende plot oplevert.
Deze grafiek is zeer interessant en toont ons de posterior distributie van de simulaties van het model dat we hierboven hebben getoond. De plot geeft ons een idee van de variatie van alle parameters, maar de coëfficiënten liggen op zulke verschillende schalen dat de details verloren gaan door ze allemaal samen weer te geven.
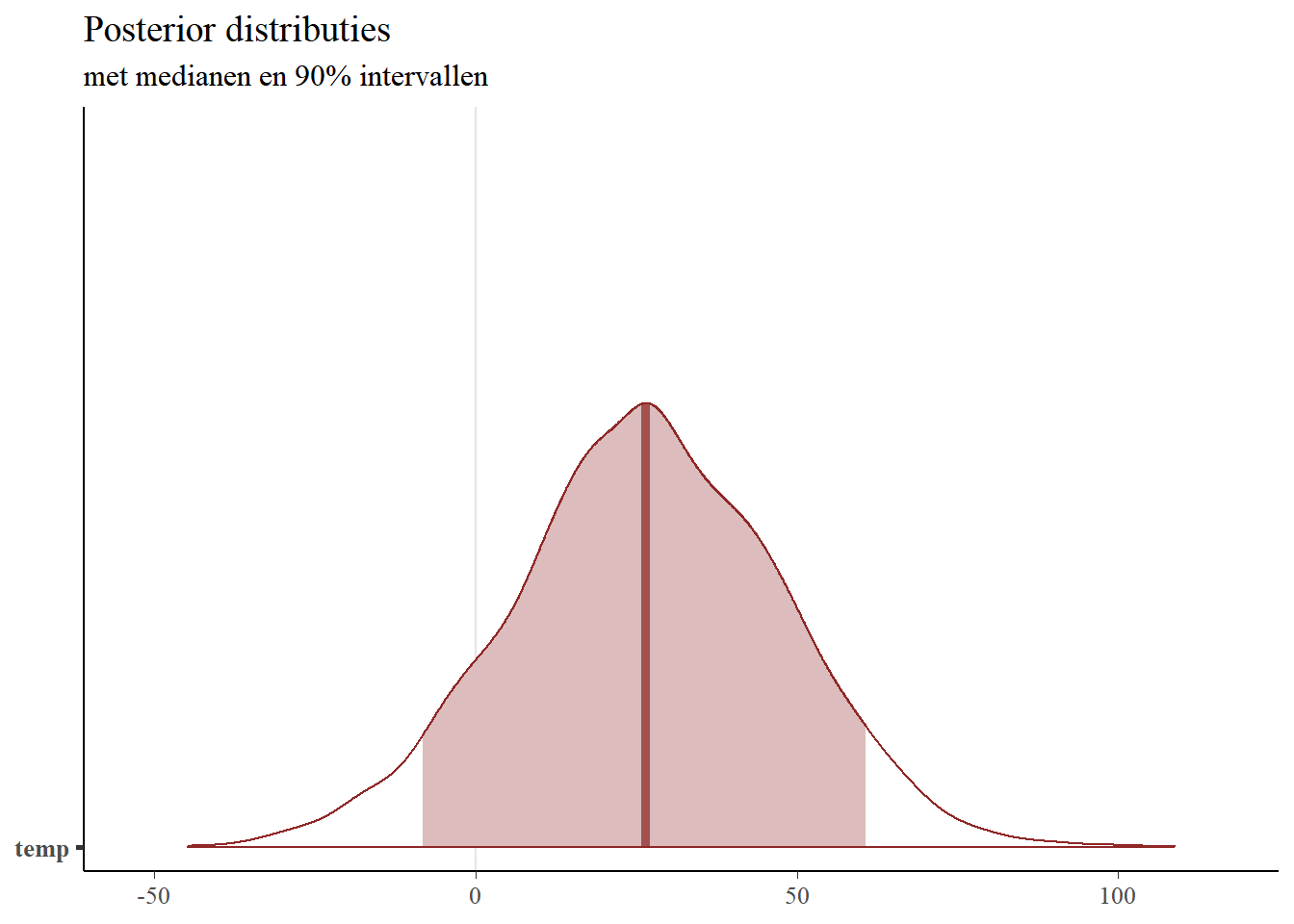
Laten we ons concentreren op de temperatuurcoëfficiënt en een gebiedsplot maken met alleen deze parameter:
# area plot van temperatuur parametermcmc_areas(sims,pars =c("temp"),prob =0.90) + plot_title
Deze grafiek toont de mediaan van de verdeling (26,69, die zeer dicht bij ons gemiddelde van 26,83 ligt). We kunnen de grenzen van het hierboven getoonde gearceerde gebied bepalen met de posterior_interval functie, of rechtstreeks uit de simulaties zelf:
posterior_interval(fit_1, pars ="temp", prob=.9)
5% 95%
temp -8.21517 60.75168
# of rechtstreeks van de posterior distributionquantile(sims[,2], probs =c(.05,.95))
5% 95%
-8.21517 60.75168
Beide methoden geven hetzelfde resultaat.
Visualiseren van slopes van de posterior distributie
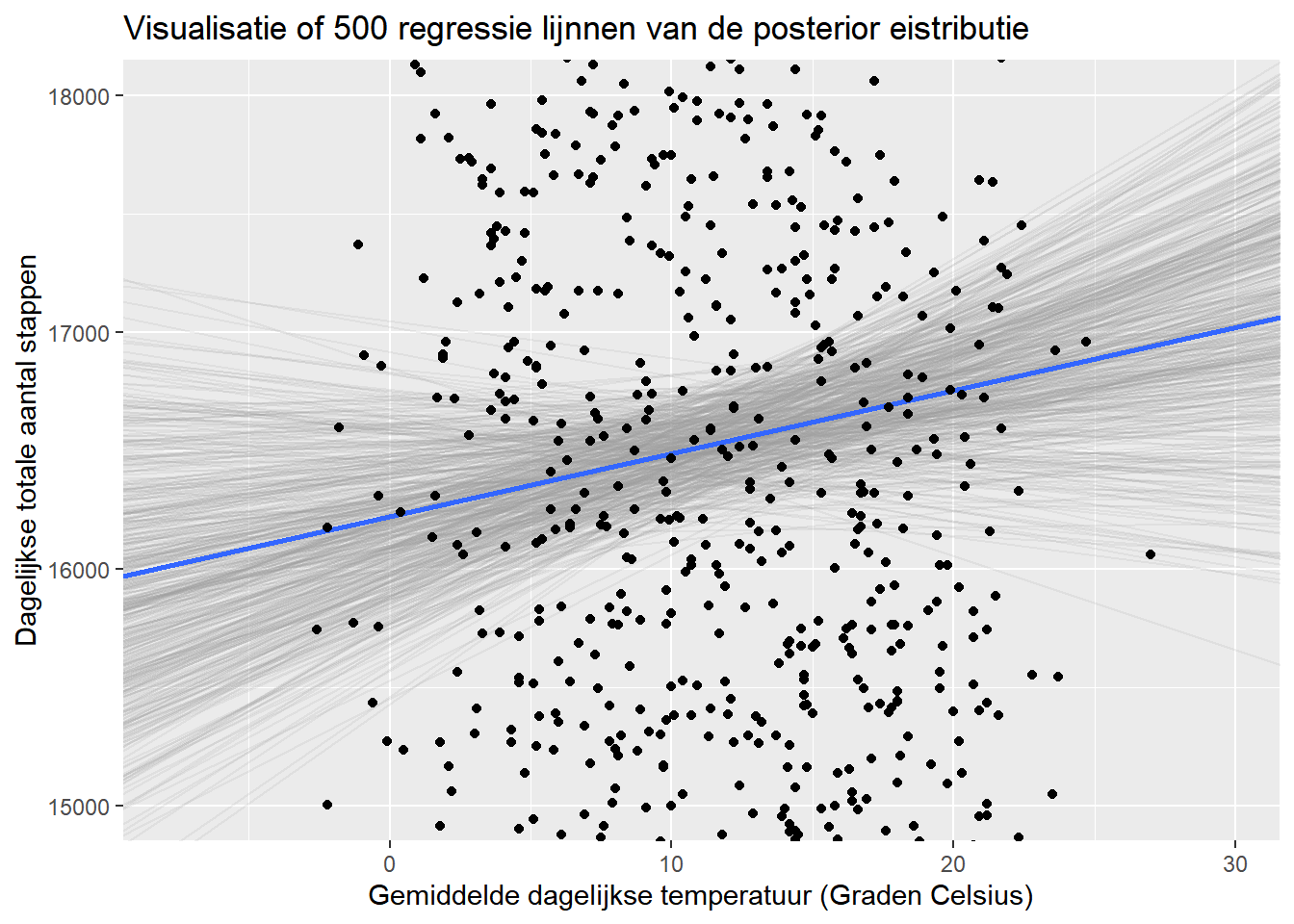
Een andere interessante manier om de verschillende coëfficiënten uit de posterior verdeling te visualiseren is door de regressielijnen van vele simulaties uit de posterior distributie gelijktijdig uit te zetten tegen de ruwe data. Deze visualisatietechniek wordt veel gebruikt in zowel Richard McElreath’s Statistical Rethinking als in Gelmans Regression and Other Stories. Beide boeken maken dit soort tekeningen met behulp van plotfuncties in basis-R. Ik was erg blij deze blog post te vinden met een voorbeeld van hoe je deze plots kan maken met behulp van ggplot2! Ik heb de code lichtjes aangepast om de onderstaande figuur te maken.
De eerste stap is het extraheren van de basisinformatie om elke regressielijn te tekenen. We doen dit met de volgende code, waarbij we in essentie ons model-object doorgeven aan een dataframe, en dan enkel het intercept en de temperatuur-hellingen voor elk van onze 4.000 simulaties uit de posterior distributie houden.
Dit geeft het volgende dataframe terug:
# Dit is een data-frame van posterior samples # Een rij per sample.fits <- fit_1 %>%as_tibble() %>%rename(intercept =`(Intercept)`) %>%select(-sigma)# hoe ziet dat dataframe eruit?head(fits)
Dit dataframe heeft 4.000 rijen, één voor elke simulatie uit de posterior verdeling in onze originele sims matrix.
We stellen dan enkele “esthetische regelaars” in, die specificeren hoeveel lijnen van de posterior verdeling we willen plotten, hun transparantie (de alpha parameter), en de kleuren voor de individuele posterior lijnen en het algemene gemiddelde van de posterior schattingen. De ggplot2 code stelt dan de assen in met het originele data frame (steps_weather), plot een steekproef van regressielijnen uit de posterior verdeling in licht grijs, en plot dan de gemiddelde helling van alle posterior simulaties in blauw.
Dat levert de volgende plot op:
# Eerst de opmaak instellenn_draws <-500alpha_level <- .15color_draw <-"grey60"color_mean <-"#3366FF"# plot makenggplot(steps_weather) +# eerst - eerst de assen van de originele data bepalenaes(x = temp, y = daily_total ) +# restrictie opleggen aan y-as om de focus te leggen op de verschillende slopes in het# centrum van de datacoord_cartesian(ylim =c(15000, 18000)) +# Plot een random sample van rijen van de simulatie# als grijze semi-transparante lijnengeom_abline(aes(intercept = intercept, slope = temp), data =sample_n(fits, n_draws), color = color_draw, alpha = alpha_level ) +# Plot de gemiddelde waarden van onze parameters in blauw# dit correspondeert met de coefficienten die we terugkregen van onze # modelsamenvattinggeom_abline(intercept =mean(fits$intercept), slope =mean(fits$temp), size =1, color = color_mean ) +geom_point() +# definieer de aslabels en de titel van de plotlabs(x ='Gemiddelde dagelijkse temperatuur (Graden Celsius)', y ='Dagelijkse totale aantal stappen' , title ='Visualisatie of 500 regressie lijnnen van de posterior eistributie')
De gemiddelde helling (weergegeven in de grafiek en ook terug te vinden in de modelsamenvatting hierboven) van de temperatuur is 26,8. Maar het plotten van samples uit de posterior verdeling maakt duidelijk dat er nogal wat onzekerheid is over de grootte van deze relatie! Sommige van de hellingen uit de verdeling zijn negatief - zoals we zagen in onze berekening van de onzekerheidsintervallen hierboven. In essentie is er een “gemiddelde” coëfficiëntschatting, maar wat het Bayesiaanse raamwerk heel goed doet (via de posterior verdelingen) is extra informatie verschaffen over de onzekerheid van onze schattingen.
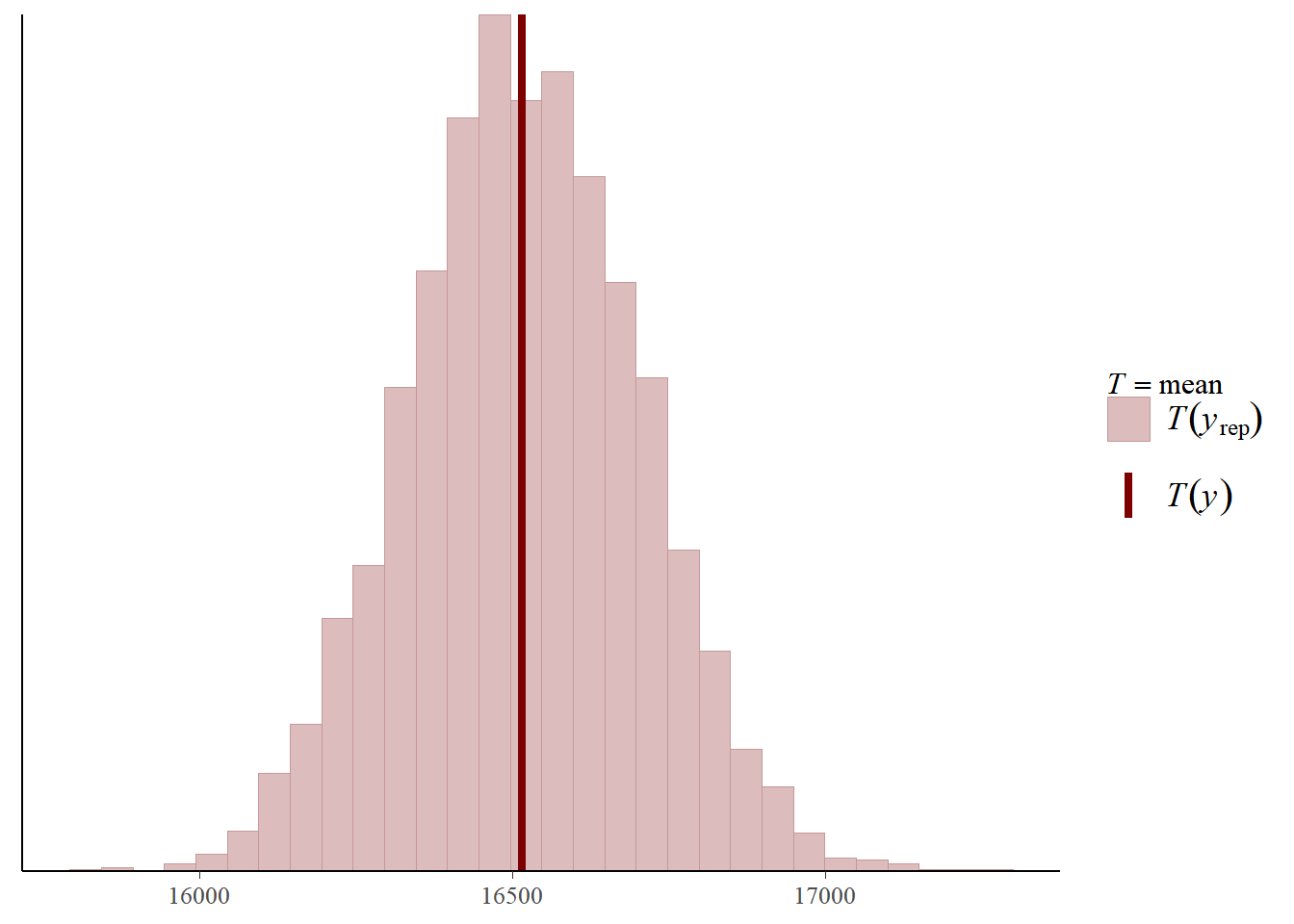
Posterior voorspellingscontroles
Een laatste manier om grafieken te gebruiken om ons model te begrijpen is door gebruik te maken van posterior predictive checks. Ik hou van deze intuïtieve manier om de logica achter deze reeks technieken uit te leggen: “Het idee achter posterior predictive checking is simpel: als een model een goede fit is, moeten we het kunnen gebruiken om gegevens te genereren die veel lijken op de gegevens die we hebben waargenomen. De gegenereerde gegevens worden de posterior predictive distributie genoemd, dat is de verdeling van de uitkomstvariabele (dagelijks totaal aantal stappen in ons geval) die wordt geïmpliceerd door een model (het regressiemodel dat hierboven is gedefinieerd). Het gemiddelde van deze verdeling wordt weergegeven in de bovenstaande uitvoer van het regressieoverzicht, met de naam mean_PPD.
Er zijn vele soorten visualisaties die men kan maken om posterieure voorspellende controles uit te voeren. Wij zullen één zo’n analyse uitvoeren (voor meer informatie over dit onderwerp), die het gemiddelde van onze uitkomstvariabele (dagelijks totaal aantal stappen) in onze oorspronkelijke dataset en de posterior predictive distributie van ons regressie model.
De code is rechttoe rechtaan.
# posterior predictive checks# https://mc-stan.org/bayesplot/reference/pp_check.html# http://mc-stan.org/rstanarm/reference/pp_check.stanreg.html# Het idee achter posterior predictive checking is eenvoudig: als een model een goede # fit heeft dan moeten we data kunnen genereren die erg lijken op de data die we hebben geobserveerd.# Om die data te genereren voor posterior predictive checks (PPCs), simuleren we die van de posterior predictive distributie. # posterior predictive check - voor meer informatie zie:# https://mc-stan.org/bayesplot/reference/pp_check.html# http://mc-stan.org/rstanarm/reference/pp_check.stanreg.htmlpp_check(fit_1, "stat")
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
We kunnen zien dat het gemiddelde van onze dagelijkse stappen variabele in de originele dataset in principe in het midden van de posterior voorspellende distributie valt. Volgens deze analyse “genereert ons regressiemodel gegevens die veel lijken op de gegevens die we hebben geobserveerd!”
Het model gebruiken om voorspellingen te doen met nieuwe gegevens
Tenslotte zullen we het model gebruiken om voorspellingen te doen over het aantal stappen per dag, gebaseerd op een specifieke waarde van de gemiddelde dagtemperatuur. In Regression and Other Stories bespreken de auteurs in hoofdstuk 9 hoe een Bayesiaans regressiemodel kan worden gebruikt om voorspellingen te doen op een aantal verschillende manieren, waarbij telkens verschillende niveaus van onzekerheid in de voorspellingen worden opgenomen. Wij zullen elk van deze methoden achtereenvolgens toepassen.
Voor elk van de onderstaande methoden zullen we het gemiddelde aantal stappen per dag voorspellen wanneer de temperatuur 10 graden Celsius bedraagt. We kunnen een nieuw dataframe opzetten dat we zullen gebruiken om de modelvoorspellingen te verkrijgen:
# Gebruik het model om voorspellingen te doen# defineer nieuwe data van waaruit we deze voorspellingen maken # we doen voorspellingen voor het geval de gemiddelde dagtemperatuur 10 graden Celsius is for when the average daily temperature new <-data.frame(temp =10)
Puntvoorspellingen met behulp van de samenvattingen van de afzonderlijke waardecoëfficiënten van de posterieure verdelingen
De eerste benadering komt overeen met die welke we zouden gebruiken bij een klassieke regressieanalyse. We gebruiken gewoon de puntschattingen uit de modelsamenvatting, voegen de nieuwe temperatuur in waarvoor we een voorspelling willen, en produceren onze voorspelling in de vorm van een enkel getal. We kunnen dit doen met de predict functie in R, of door de coëfficiënten uit onze modelsamenvatting te vermenigvuldigen. Beide methoden leveren dezelfde voorspelling op:
# gebruik simpel de puntsamenvatting van de posterio distributie # voor de modelcoefficienten (van de modelsamenvatting van hierboven)y_point_est <-predict(fit_1, newdata = new)# zelfde predictie "met de hand"y_point_est_2 <-mean(sims[,1]) +mean(sims[,2])*new
Beide leveren een puntvoorspelling van 16483.71.
# ze zijn hetzelfde predict(fit_1, newdata = new)
1
16485.1
mean(sims[,1]) +mean(sims[,2])*new
temp
1 16485.1
Lineaire voorspellingen met onzekerheid (in de interceptie + temperatuurcoëfficiënten)
We kunnen echter genuanceerder zijn in onze voorspelling van het dagelijkse totale aantal stappen. Het hierboven berekende regressiemodel geeft 4.000 simulaties voor drie parameters - de intercept, de temperatuurcoëfficiënt, en sigma (de standaardafwijking van de residuen).
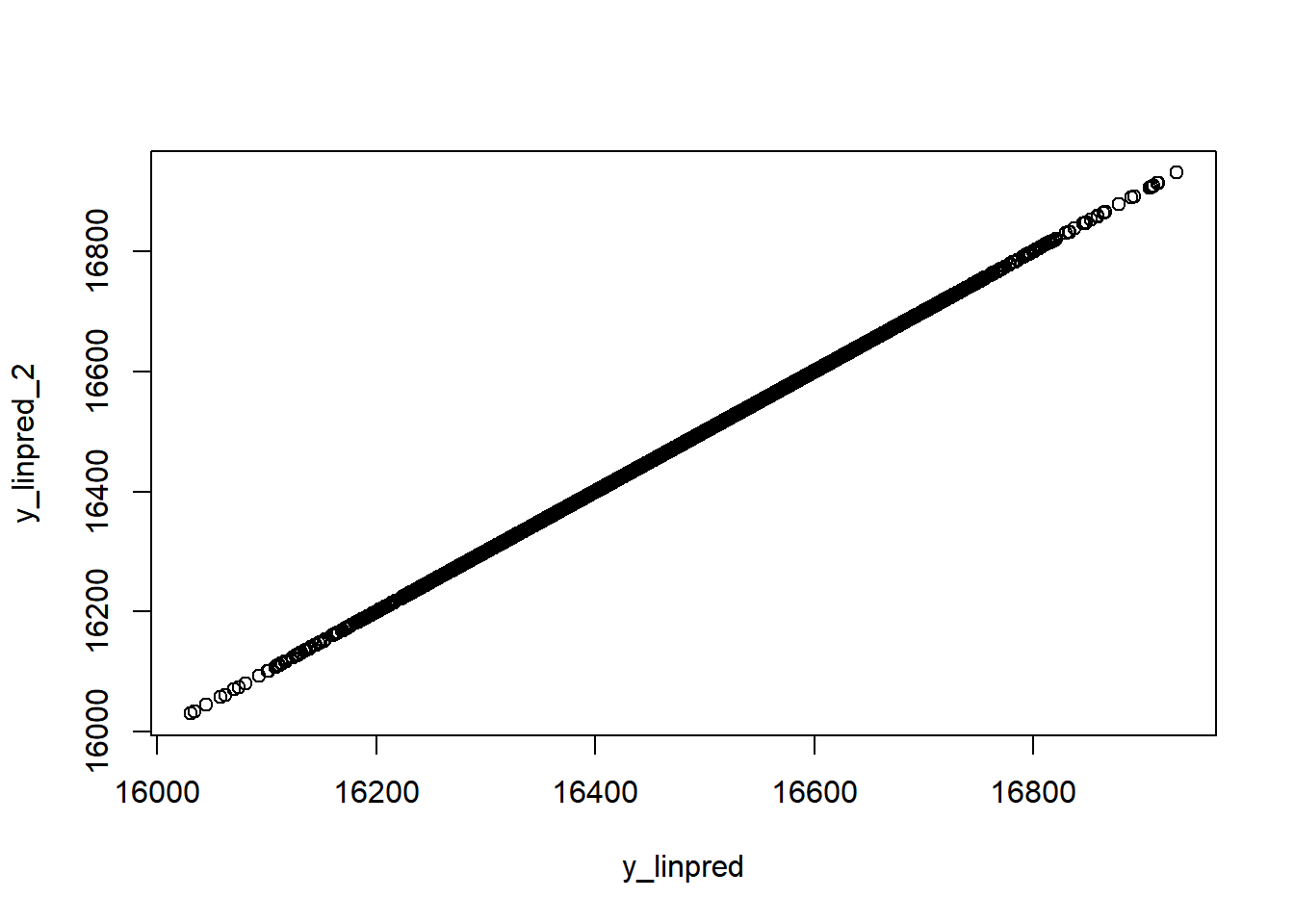
De volgende methode is geïmplementeerd in rstanarm met de posterior_linpred functie, en we kunnen deze gebruiken om de voorspellingen direct te berekenen. We kunnen hetzelfde resultaat ook “met de hand” berekenen met behulp van de matrix van simulaties uit de posterior verdeling van onze coëfficiëntschattingen. Bij deze aanpak wordt gewoon de temperatuur ingevoerd waarvoor wij voorspellingen willen (10 graden Celsius) en wordt voor elk van de simulaties het intercept opgeteld bij de temperatuurcoëfficiënt maal 10. Beide methoden leveren dezelfde vector van 4.000 voorspellingen op:
# lineaire predictor met onzekerheid met gebruikmaking van posterior_linpredy_linpred <-posterior_linpred(fit_1, newdata = new)# uitrekenen "met de hand" # we gebruiken de sims matrix die we hierboven definieerden # sims <- as.matrix(fit_1)y_linpred_2 <- sims[,1] + (sims[,2]*10)
Dat geeft dezelfde resultaten.
# check - ze zijn hetzelfde!plot(y_linpred,y_linpred_2)
cor.test(y_linpred, y_linpred_2)
Pearson's product-moment correlation
data: y_linpred and y_linpred_2
t = Inf, df = 3998, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
1 1
sample estimates:
cor
1
Posterior Predictive Distributies met de onzekerheid in de coëfficiëntschattingen en in sigma
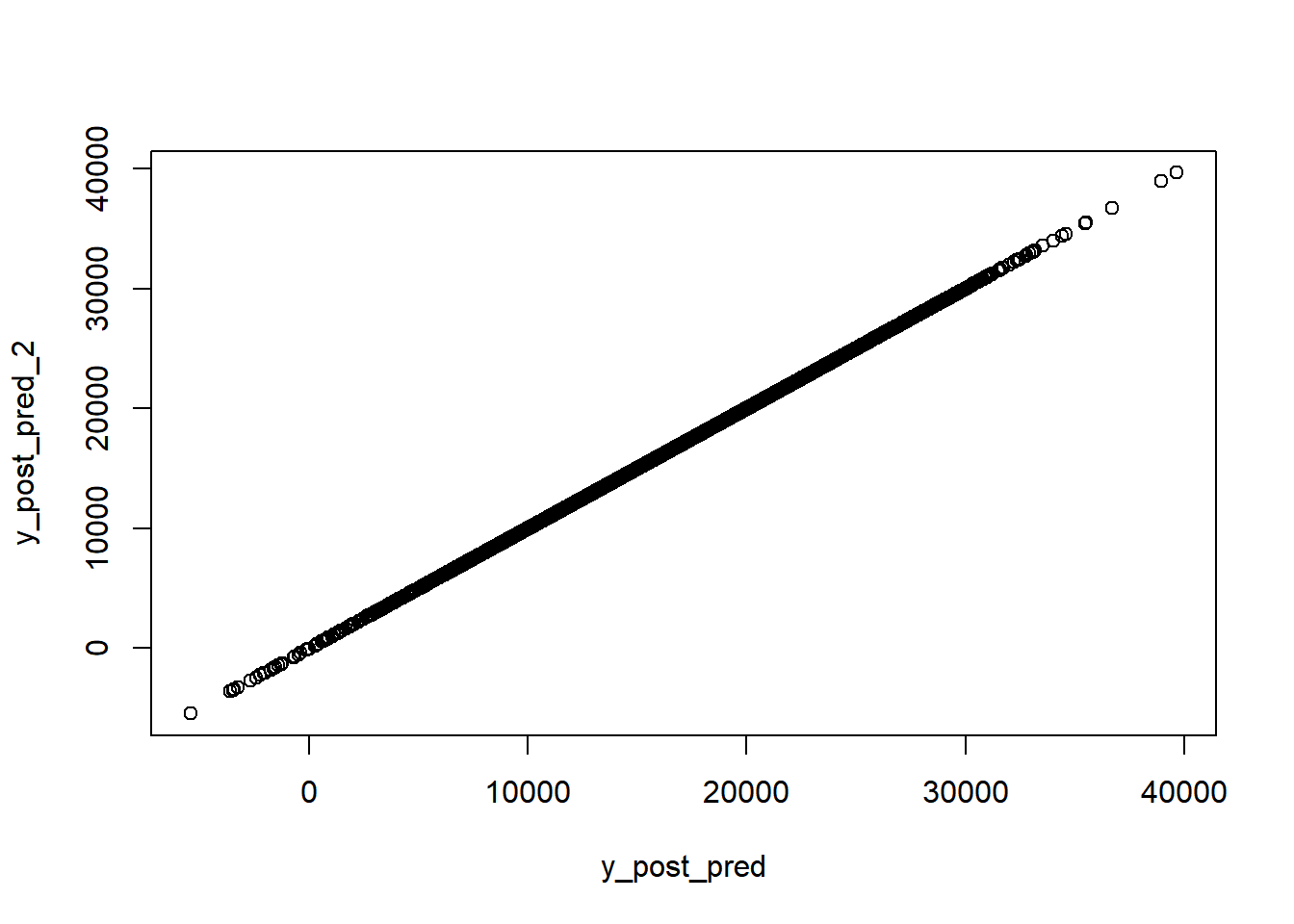
De laatste voorspellingsmethode voegt nog een extra laag van onzekerheid toe aan onze voorspellingen, door de posterior verdelingen voor sigma mee te nemen in de berekeningen. Deze methode is beschikbaar via de functie posterior_predict, en we gebruiken opnieuw onze matrix van 4.000 simulaties om een vector van 4.000 voorspellingen te berekenen.
De posterior predict methode volgt de aanpak van de posterior_linpred functie hierboven, maar voegt een extra foutterm toe gebaseerd op onze schattingen van sigma, de standaardafwijking van de residuen. De berekening zoals getoond in het “met de hand” gedeelte van de code hieronder maakt. Het maakt duidelijk waar de willekeurigheid in het spel komt, en vanwege deze willekeurigheid zullen de resultaten van de posterior_predict functie en de “met de hand” berekening niet overeenkomen tenzij we dezelfde seed instellen voordat we elke berekening uitvoeren. Beide methoden leveren een vector van 4.000 voorspellingen op.
# predictive distributie voor een nieuwe observatie met gebruik van posterior_predictset.seed(1)y_post_pred <-posterior_predict(fit_1, newdata = new)
# check - ze zijn hetzelfde!plot(y_post_pred, y_post_pred_2)
cor.test(y_post_pred, y_post_pred_2)
Pearson's product-moment correlation
data: y_post_pred and y_post_pred_2
t = Inf, df = 3998, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
1 1
sample estimates:
cor
1
Visualisatie van de drie soorten voorspellingen
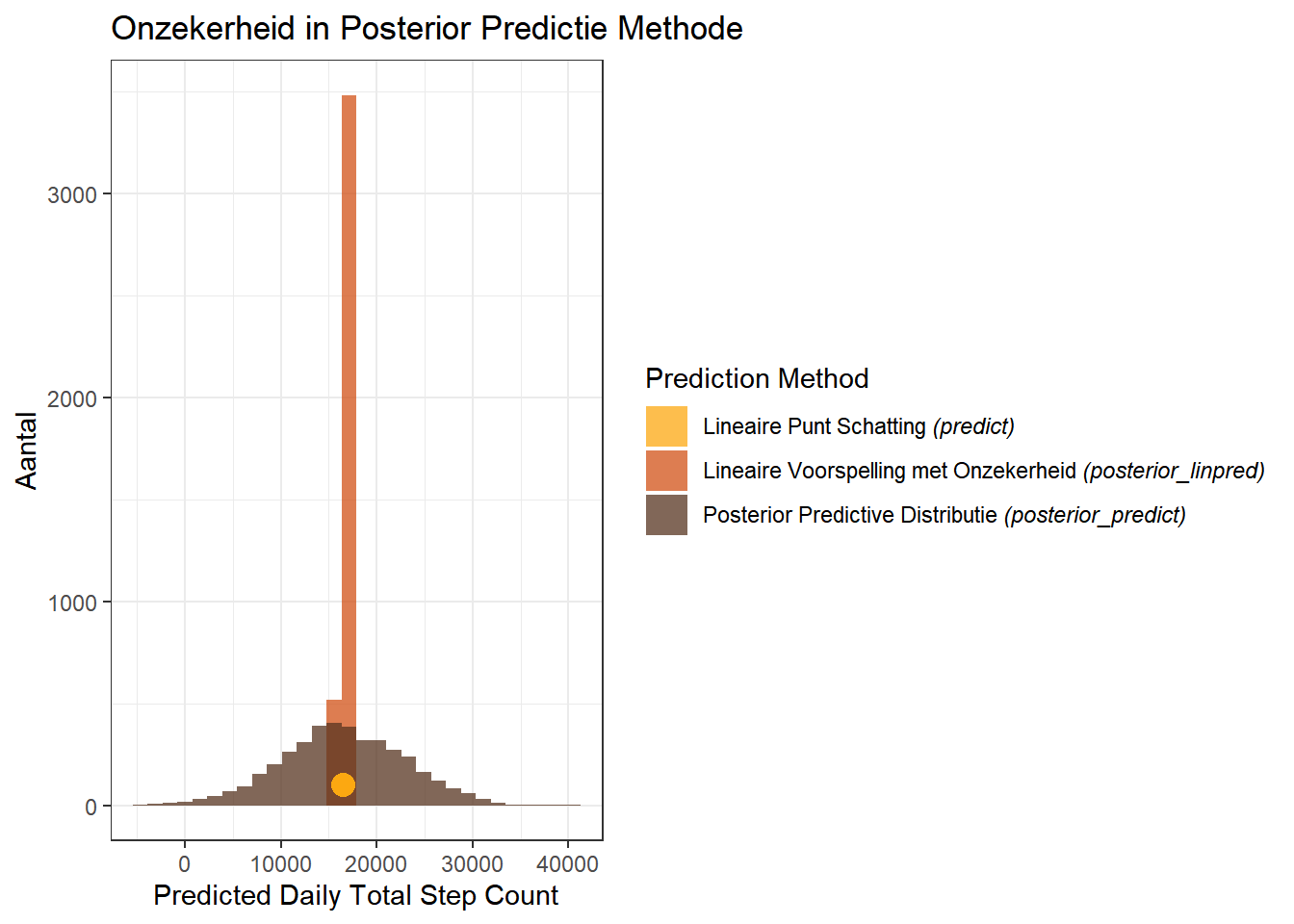
Laten we een visualisatie maken die de resultaten weergeeft van de voorspellingen die we hierboven deden. We kunnen een enkele cirkel gebruiken om de puntvoorspelling van de regressiecoëfficiënten weer te geven in de modelsamenvatting, en histogrammen om de posterior verdelingen weer te geven die geproduceerd zijn door de lineaire voorspelling met onzekerheid (posterior_linpred) en posterior predictive distribution (posterior_predict) methoden die hierboven beschreven zijn.
We zetten eerst de vectoren van posterior verdelingen die we hierboven hebben gemaakt in een dataframe. We maken ook een dataframe met de enkele puntvoorspelling van onze lineaire voorspelling. Vervolgens stellen we ons kleurenpalet in (afkomstig uit het NineteenEightyR pakket) en maken dan de plot:
# creeer een dataframe die de waarden van de posterior distributies omvat # van de voorspellingen van de totaal aantal dagelijkse stappen bij 10 grade Celciuspost_dists <-as.data.frame(rbind(y_linpred, y_post_pred)) %>%setNames(c('prediction'))post_dists$pred_type <-c(rep('posterior_linpred', 4000),rep('posterior_predict', 4000))y_point_est_df =as.data.frame(y_point_est)
Dat geeft de volgende plot:
# 70 en meer kleuren - via NineteenEightyR pakket# https://github.com/m-clark/NineteenEightyRpal <-c('#FEDF37', '#FCA811', '#D25117', '#8A4C19', '#573420')ggplot(data = post_dists, aes(x = prediction, fill = pred_type)) +geom_histogram(alpha = .75, position="identity") +geom_point(data = y_point_est_df,aes(x = y_point_est,y =100,fill ='Linear Point Estimate'),color = pal[2],size =4,# alpha = .75,show.legend = F) +scale_fill_manual(name ="Prediction Method",values =c(pal[c(2,3,5)]),labels =c(bquote(paste("Lineaire Punt Schatting ", italic("(predict)"))),bquote(paste("Lineaire Voorspelling met Onzekerheid " , italic("(posterior_linpred)"))),bquote(paste("Posterior Predictive Distributie ", italic("(posterior_predict)"))))) +# set the plot labels and titlelabs(x ="Predicted Daily Total Step Count", y ="Aantal", title ='Onzekerheid in Posterior Predictie Methode') +theme_bw()
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Deze grafiek is zeer informatief en maakt duidelijk hoe groot de onzekerheid is die we voor elk van onze voorspellingsmethoden krijgen. Hoewel alle drie voorspellingsmethoden op dezelfde plaats op de x-as gecentreerd zijn, verschillen zij sterk wat betreft de onzekerheid rond de voorspellingsramingen.
De puntvoorspelling is een enkele waarde en bevat als zodanig geen onzekerheid. De lineaire voorspelling met onzekerheid, die rekening houdt met de posterior verdeling van onze interceptie- en temperatuurcoëfficiënten, heeft een zeer scherpe piek, waarbij de modelschattingen binnen een relatief klein bereik variëren. De posterior predictive distributie varieert veel meer, met het laagste bereik van de verdeling onder nul, en het hoogste bereik van de verdeling boven 40.000!
Samenvatting en conclusie
In dit artikel hebben we een eenvoudig model gemaakt met behulp van het rstanarm pakket in R, om te leren over Bayesiaanse regressie analyse. We gebruikten een dataset bestaande uit mijn geschiedenis van dagelijkse totale stappen, en bouwden een regressie model om het dagelijkse aantal stappen te voorspellen uit de dagelijkse gemiddelde temperatuur in graden Celsius. In tegenstelling tot de gewone kleinste kwadraten benadering die puntschattingen van modelcoëfficiënten oplevert, geeft de Bayesiaanse regressie posterior verdelingen van de coëfficiëntschattingen. Wij hebben een aantal verschillende samenvattingen en visualisaties van deze posterior verdelingen gemaakt om de coëfficiënten en de Bayesiaanse benadering in het algemeen te begrijpen - A) het gebruik van het bayesplot pakket om de posterior verdelingen van onze coëfficiënten te visualiseren
B) het plotten van 500 hellingen van de posterior verdeling, en
C) het uitvoeren van een controle van de posterior predictive distributie.