De laatste tijd heeft Julia Silge een aantal videoopnamen gemaakt die laten zien hoe het tidymodels raamwerk is te gebruiken.Het zijn opnamen over de eerste stappen in het modelleren tot hoe complexe modellen zijn te evalueren. Deze videoopname is goed voor mensen die net beginnen met tidymodels. Ze maakt daarbij gebruik van een #TidyTuesday dataset over pinguïns. Hier gaat het om classificeren.
De laatste tijd heeft Julia Silge een aantal videoopnamen gemaakt die laten zien hoe het tidymodels raamwerk is te gebruiken.Het zijn opnamen over de eerste stappen in het modelleren tot hoe complexe modellen zijn te evalueren. Deze videoopname is goed voor mensen die net beginnen met tidymodels. Ze maakt daarbij gebruik van een #TidyTuesday dataset over pinguïns. Hier gaat het om classificeren.
v ggplot2 3.3.6 v purrr 0.3.4
v tibble 3.1.7 v dplyr 1.0.9
v tidyr 1.2.0 v stringr 1.4.1
v readr 2.1.2 v forcats 0.5.1
Warning: package 'ggplot2' was built under R version 4.1.3
Warning: package 'tibble' was built under R version 4.1.3
Warning: package 'tidyr' was built under R version 4.1.3
Warning: package 'readr' was built under R version 4.1.3
Warning: package 'dplyr' was built under R version 4.1.3
Warning: package 'stringr' was built under R version 4.1.3
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
library(palmerpenguins)
Warning: package 'palmerpenguins' was built under R version 4.1.3
penguins
# A tibble: 344 x 8
species island bill_length_mm bill_depth_mm flipper_~1 body_~2 sex year
<fct> <fct> <dbl> <dbl> <int> <int> <fct> <int>
1 Adelie Torgersen 39.1 18.7 181 3750 male 2007
2 Adelie Torgersen 39.5 17.4 186 3800 fema~ 2007
3 Adelie Torgersen 40.3 18 195 3250 fema~ 2007
4 Adelie Torgersen NA NA NA NA <NA> 2007
5 Adelie Torgersen 36.7 19.3 193 3450 fema~ 2007
6 Adelie Torgersen 39.3 20.6 190 3650 male 2007
7 Adelie Torgersen 38.9 17.8 181 3625 fema~ 2007
8 Adelie Torgersen 39.2 19.6 195 4675 male 2007
9 Adelie Torgersen 34.1 18.1 193 3475 <NA> 2007
10 Adelie Torgersen 42 20.2 190 4250 <NA> 2007
# ... with 334 more rows, and abbreviated variable names 1: flipper_length_mm,
# 2: body_mass_g
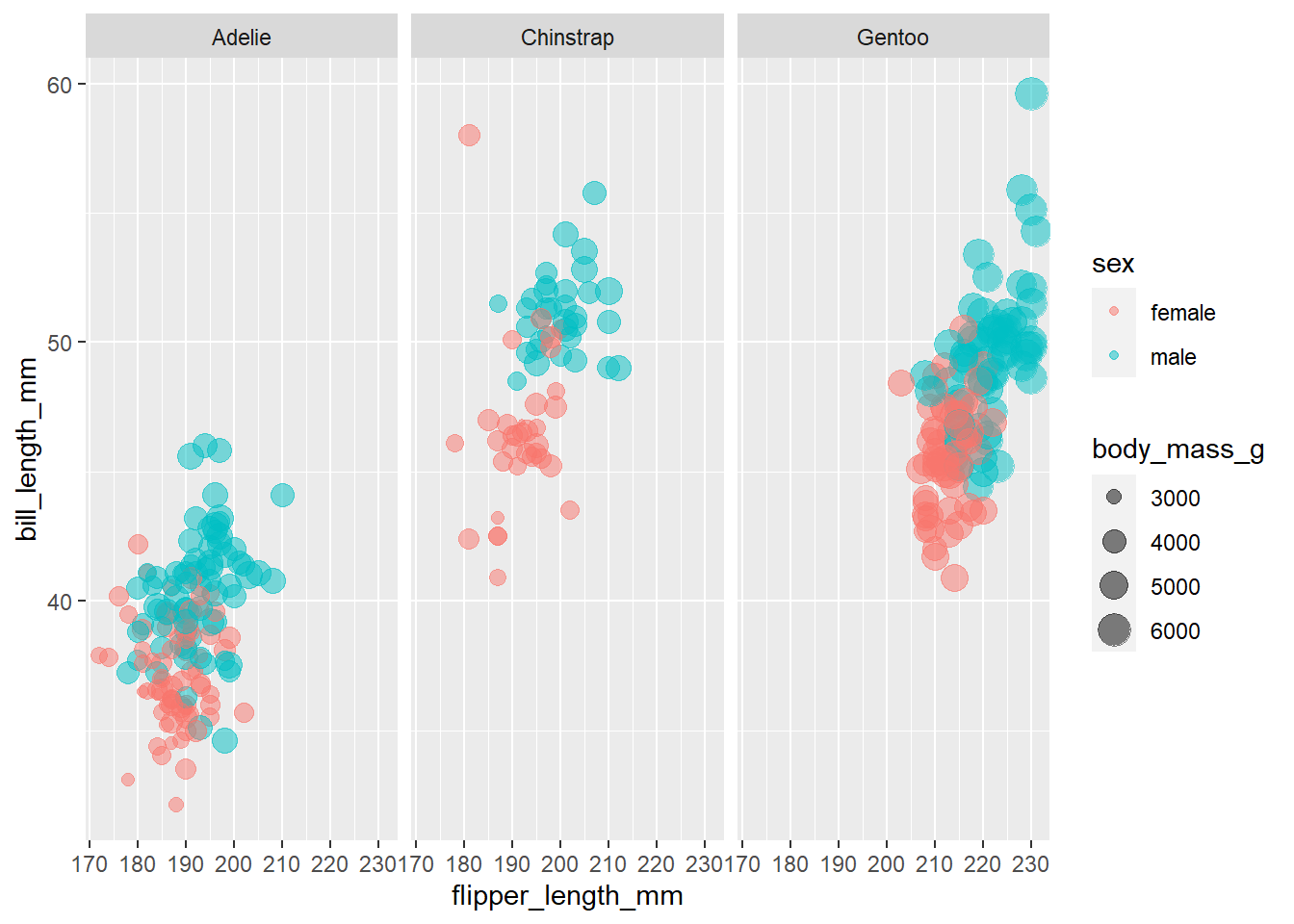
Als je een classificatiemodel voor soorten pinquins probeert op te stellen, zul je waarschijnlijk een bijna perfecte pasvorm vinden, omdat dit soort waarnemingen in feite de verschillende soorten onderscheiden. sex (geslacht) daarentegen geeft een wat rommeliger beeld, vandaar dat hier deze uitkomstvariabelen op basis van predictoren wordt voorspeld.
Het ziet er naar uit dat de vrouwelijke pinguïnflippers kleiner zijn met kleinere snavels, maar laten we ons klaarmaken voor het modelleren om meer te weten te komen! De informatie over het eiland of het jaar zullen we niet gebruiken in ons model. Die halen we eruit.
v broom 0.8.0 v rsample 0.1.1
v dials 1.0.0 v tune 0.2.0
v infer 1.0.2 v workflows 0.2.6
v modeldata 0.1.1 v workflowsets 0.2.1
v parsnip 1.0.0 v yardstick 1.0.0
v recipes 0.2.0
Warning: package 'broom' was built under R version 4.1.3
Warning: package 'dials' was built under R version 4.1.3
Warning: package 'scales' was built under R version 4.1.3
Warning: package 'infer' was built under R version 4.1.3
Warning: package 'parsnip' was built under R version 4.1.3
Warning: package 'recipes' was built under R version 4.1.3
Warning: package 'tune' was built under R version 4.1.3
Warning: package 'workflows' was built under R version 4.1.3
Warning: package 'workflowsets' was built under R version 4.1.3
Warning: package 'yardstick' was built under R version 4.1.3
-- Conflicts ----------------------------------------- tidymodels_conflicts() --
x scales::discard() masks purrr::discard()
x dplyr::filter() masks stats::filter()
x recipes::fixed() masks stringr::fixed()
x dplyr::lag() masks stats::lag()
x yardstick::spec() masks readr::spec()
x recipes::step() masks stats::step()
* Learn how to get started at https://www.tidymodels.org/start/
Omdat het een relatieve kleine dataset betreft (zeker de testset), maken we vervolgens hier gebruik van bootstrap-resamples van de trainingsgegevens, om onze modellen te evalueren.
Laten we eens twee verschillende modellen vergelijken, een logistisch regressiemodel en een random forest model. We beginnen met het maken van de modelspecificaties voor beide modellen.
Random Forest Model Specification (classification)
Computational engine: ranger
Laten we nu beginnen met het samenstellen van een tidymodels workflow(), een object dat helpt om modelleer-pijplijnen te beheren met stukjes die in elkaar passen als Lego-blokjes. Merk op dat er nog geen model is:
Warning: package 'ranger' was built under R version 4.1.3
rf_rs
# Resampling results
# Bootstrap sampling
# A tibble: 25 x 5
splits id .metrics .notes .predictions
<list> <chr> <list> <list> <list>
1 <split [249/93]> Bootstrap01 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
2 <split [249/91]> Bootstrap02 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
3 <split [249/90]> Bootstrap03 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
4 <split [249/91]> Bootstrap04 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
5 <split [249/85]> Bootstrap05 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
6 <split [249/87]> Bootstrap06 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
7 <split [249/94]> Bootstrap07 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
8 <split [249/88]> Bootstrap08 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
9 <split [249/95]> Bootstrap09 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
10 <split [249/89]> Bootstrap10 <tibble [2 x 4]> <tibble [0 x 3]> <tibble>
# ... with 15 more rows
Wij hebben elk van onze kandidaat-modellen aangepast aan onze opnieuw bemonsterde trainingsreeks!
Het model evalueren.
Laten we nu eens kijken hoe we het gedaan hebben. Eerst het logistisch regressiemodel.
collect_metrics(glm_rs)
# A tibble: 2 x 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 accuracy binary 0.918 25 0.00639 Preprocessor1_Model1
2 roc_auc binary 0.979 25 0.00254 Preprocessor1_Model1
Goed zo! De functie collect_metrics() extraheert en formatteert de .metrics kolom van resampling resultaten zoals hierboven voor het glm-model. Nu het random-forest model.
collect_metrics(rf_rs)
# A tibble: 2 x 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 accuracy binary 0.912 25 0.00547 Preprocessor1_Model1
2 roc_auc binary 0.977 25 0.00202 Preprocessor1_Model1
Dus… ook geweldig! Als ik in een situatie zit waarin een complexer model (zoals een random forest) hetzelfde presteert als een eenvoudiger model (zoals logistische regressie), dan kies ik het eenvoudiger model. Laten we eens dieper ingaan op hoe het het doet. Bijvoorbeeld, hoe voorspelt het glm-model de twee klassen?
glm_rs %>%conf_mat_resampled()
# A tibble: 4 x 3
Prediction Truth Freq
<fct> <fct> <dbl>
1 female female 41.1
2 female male 3
3 male female 4.4
4 male male 42.3
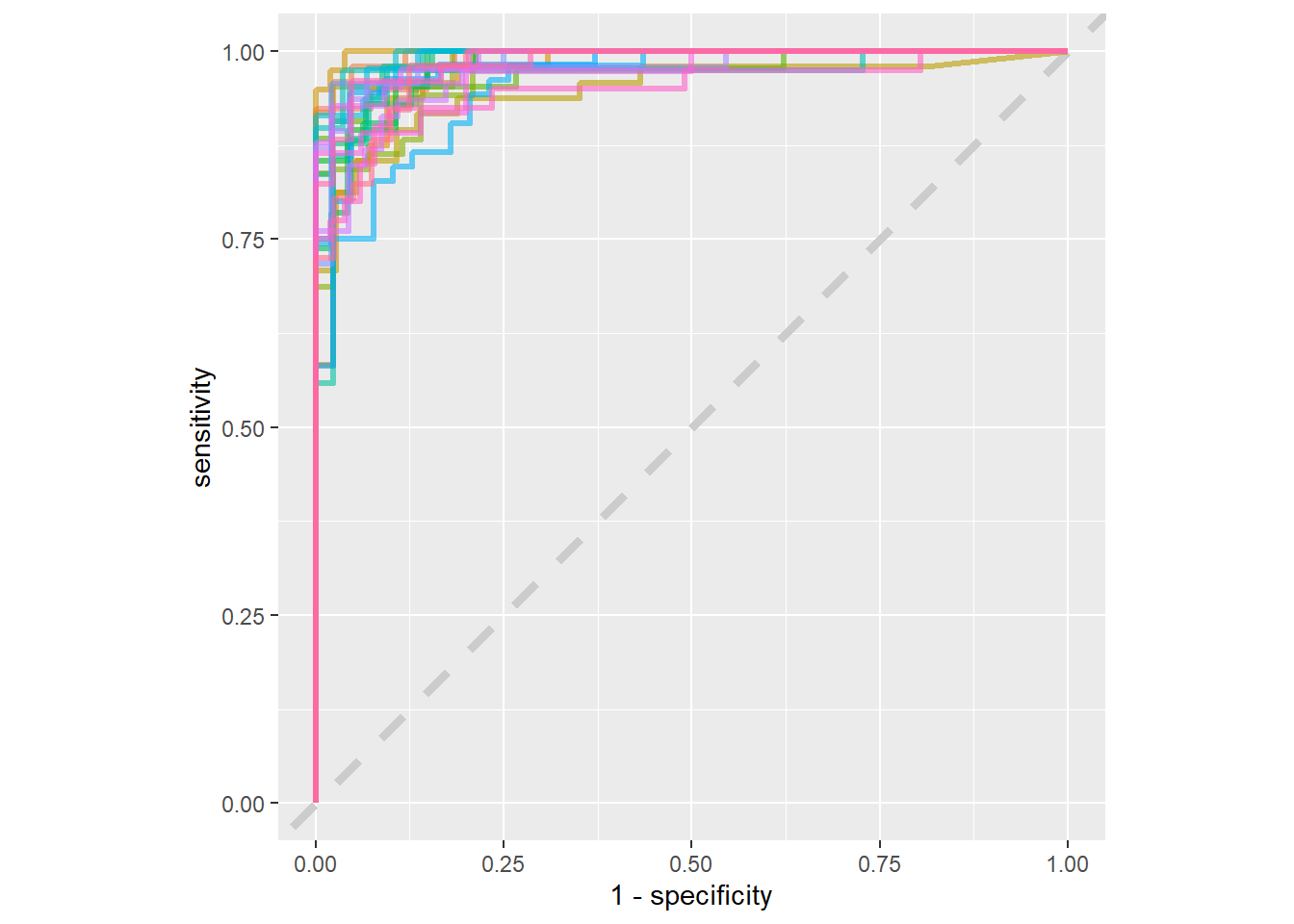
Ongeveer hetzelfde, wat goed is. We kunnen ook een ROC curve maken.
Deze ROC-curve is grilliger dan andere die u wellicht hebt gezien omdat de dataset klein is.
Het is eindelijk tijd om terug te keren naar de testset. Merk op dat we de testset tijdens deze hele analyse nog niet hebben gebruikt; de testset is kostbaar en kan alleen worden gebruikt om de prestaties op nieuwe gegevens in te schatten. Laten we nog een keer passen op de trainingsgegevens en evalueren op de testgegevens met behulp van de functie last_fit().
Truth
Prediction female male
female 37 7
male 5 35
De coëfficiënten (die we eruit kunnen halen met tidy()) zijn geschat met behulp van de trainingsdata. Als we exponentiate = TRUE gebruiken, hebben we odds ratio’s.
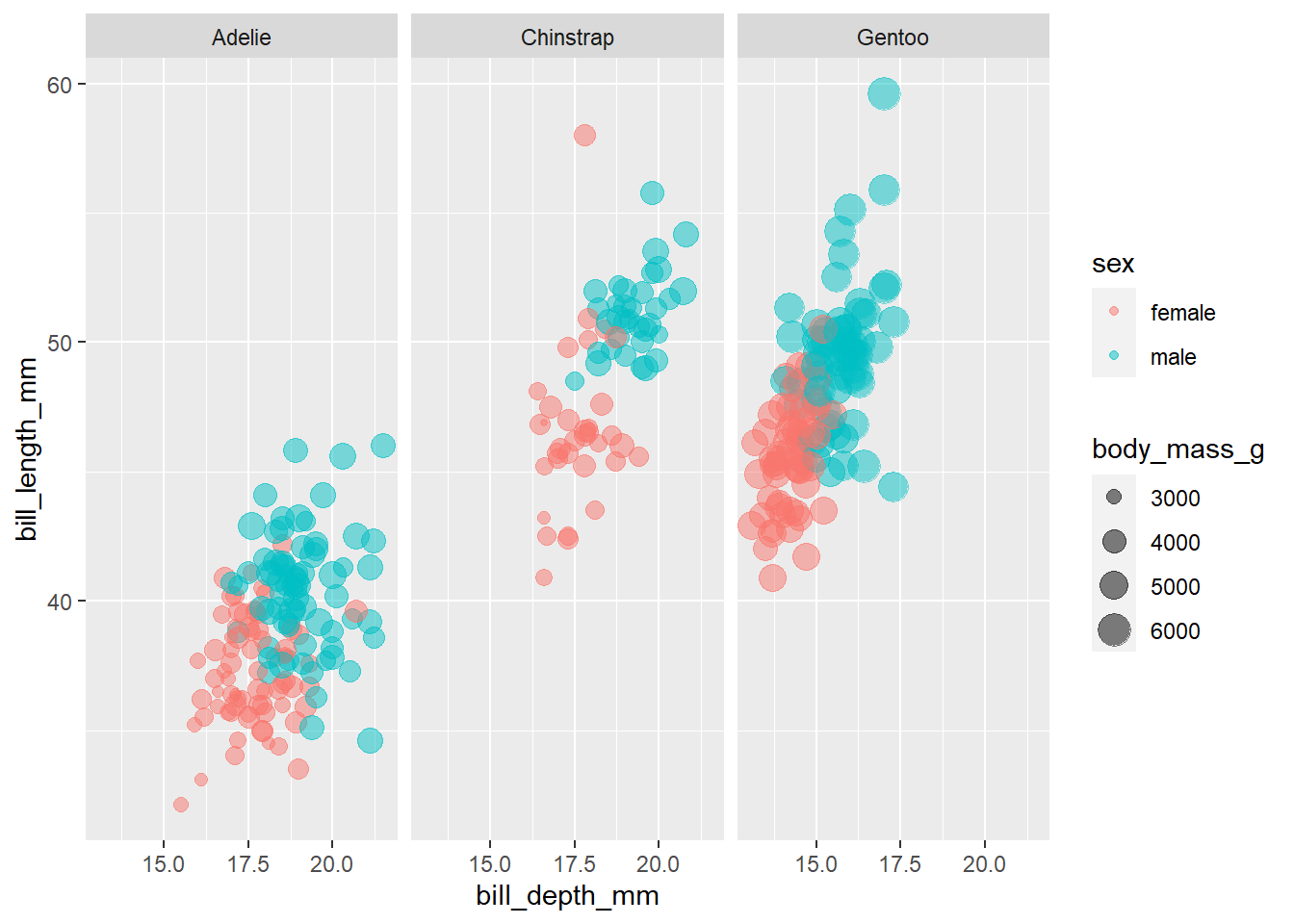
De grootste kansverhouding geldt voor de snaveldiepte, en de op één na grootste voor de snavellengte. Een toename van 1 mm snaveldiepte komt overeen met bijna 4x meer kans om een mannetje te zijn. De kenmerken van de bek van een pinguïn moeten geassocieerd zijn met het geslacht.
We hebben geen sterke aanwijzingen dat de lengte van de vleugels verschillend is tussen mannelijke en vrouwelijke pinguïns, als we de andere maten controleren; misschien moeten we dat onderzoeken door de eerste grafiek te veranderen!